
1: 领域建模
本章探讨如何使用代码对业务流程进行建模,使其高度兼容 TDD(测试驱动开发)。我们将讨论为什么领域建模很重要,并将研究一些用于领域建模的关键模式:实体、值对象和领域服务。
我们的领域模型的占位符插图 是我们领域模型模式的简单视觉占位符。我们将在本章中填充一些细节,并且随着我们进入其他章节,我们将围绕领域模型构建内容,但您应该始终能够在核心找到这些小形状。
什么是领域模型?
在介绍中,我们使用了术语业务逻辑层来描述三层架构的中心层。在本书的其余部分,我们将使用术语领域模型来代替。这是来自 DDD(领域驱动设计)社区的术语,它更好地捕捉了我们想要表达的含义(有关 DDD 的更多信息,请参见下一个侧边栏)。
领域是一种花哨的说法,意思是您尝试解决的问题。您的作者目前为一家在线家具零售商工作。根据您谈论的系统,领域可能是采购和采购、产品设计或物流和交付。大多数程序员每天都在努力改进或自动化业务流程;领域是这些流程支持的一系列活动。
模型是流程或现象的地图,它捕捉了有用的属性。人类非常擅长在脑海中生成事物的模型。例如,当有人向您扔球时,您几乎可以无意识地预测它的运动,因为您对物体在空间中的运动方式有一个模型。您的模型绝不是完美的。人类对于物体在接近光速或真空中的行为方式有着可怕的直觉,因为我们的模型从未被设计来涵盖这些情况。这并不意味着模型是错误的,但这确实意味着某些预测超出了其领域。
领域模型是企业负责人对其业务的思维导图。所有企业人士都有这些思维导图——这就是人类思考复杂流程的方式。
当他们浏览这些地图时,您会发现,因为他们使用商业术语。行话在就复杂系统进行协作的人们之间自然而然地产生。
想象一下,您,我们不幸的读者,突然与您的朋友和家人一起被运送到离地球光年之外的 alien 飞船上,并且必须从第一性原理出发,弄清楚如何导航回家。
在最初的几天里,您可能只是随机按下按钮,但很快您就会了解哪些按钮做了什么,以便您可以互相给出指示。“按下闪烁的 doohickey 附近的红色按钮,然后拨动雷达 gizmo 旁边的大杠杆,”您可能会说。
几周之内,当您采用词语来描述飞船的功能时,您会变得更加精确:“增加三个货舱的氧气含量”或“打开小推进器”。几个月后,您将采用用于整个复杂流程的语言:“启动着陆序列”或“准备进行曲速飞行”。这个过程会非常自然地发生,而无需任何正式的努力来构建共享词汇表。
商业的世俗世界也是如此。业务干系人使用的术语代表了对领域模型的提炼理解,其中复杂的想法和流程被简化为一个词或短语。
当我们听到我们的业务干系人使用不熟悉的词语,或以特定的方式使用术语时,我们应该倾听以理解更深层的含义,并将他们来之不易的经验编码到我们的软件中。
我们将在本书中通篇使用真实的领域模型,特别是来自我们目前雇主的模型。MADE.com 是一家成功的家具零售商。我们从世界各地的制造商采购家具,并在欧洲各地销售。
当您购买沙发或咖啡桌时,我们必须弄清楚如何最好地将您的货物从波兰或中国或越南运到您的起居室。
在较高的层面上,我们有独立的系统负责购买库存、向客户销售库存以及将货物运送给客户。中间的系统需要通过将库存分配给客户的订单来协调流程;参见 分配服务的上下文图。
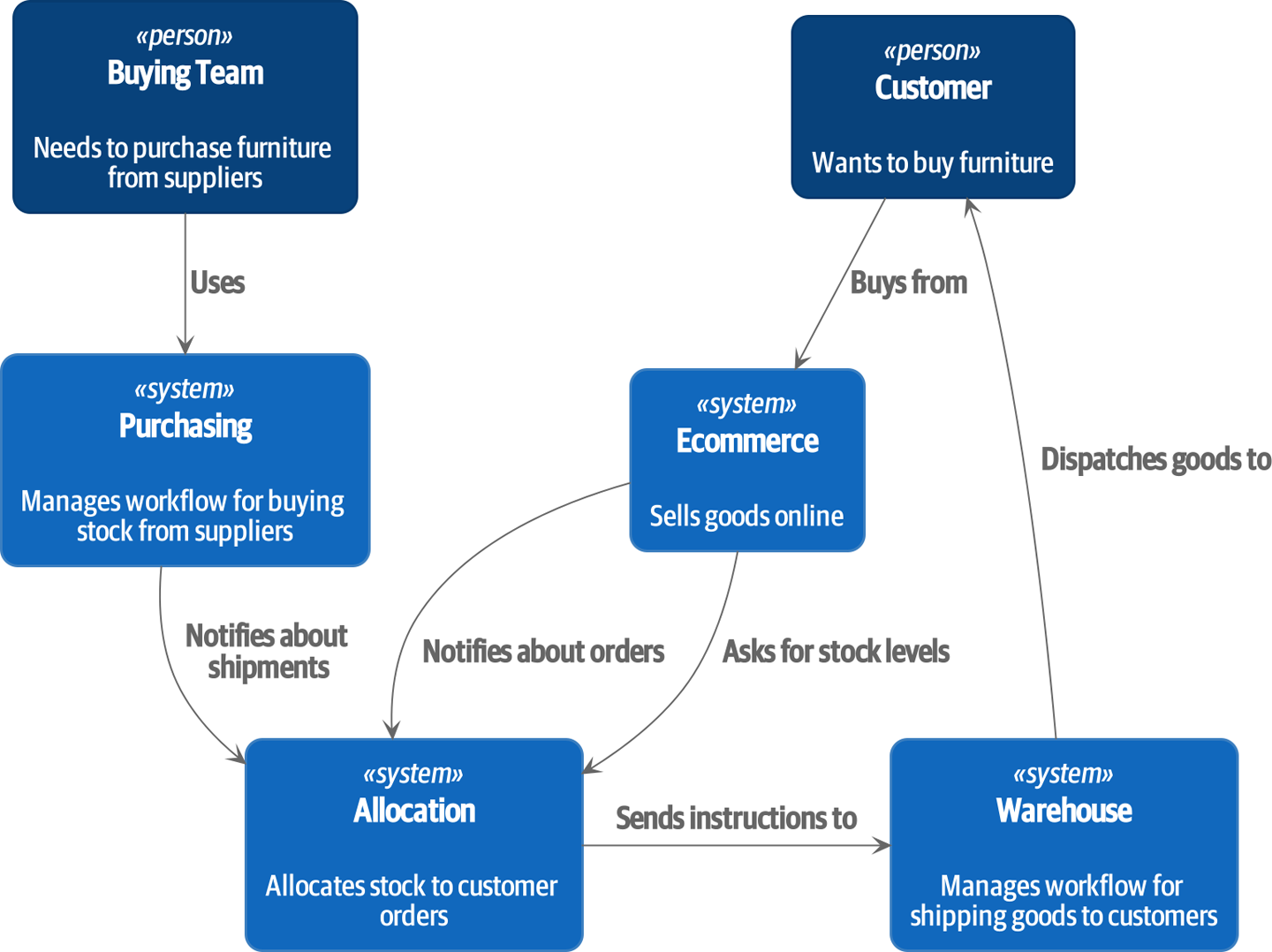
[plantuml, apwp_0102] @startuml Allocation Context Diagram !include images/C4_Context.puml scale 2 System(systema, "Allocation", "Allocates stock to customer orders") Person(customer, "Customer", "Wants to buy furniture") Person(buyer, "Buying Team", "Needs to purchase furniture from suppliers") System(procurement, "Purchasing", "Manages workflow for buying stock from suppliers") System(ecom, "Ecommerce", "Sells goods online") System(warehouse, "Warehouse", "Manages workflow for shipping goods to customers") Rel(buyer, procurement, "Uses") Rel(procurement, systema, "Notifies about shipments") Rel(customer, ecom, "Buys from") Rel(ecom, systema, "Asks for stock levels") Rel(ecom, systema, "Notifies about orders") Rel_R(systema, warehouse, "Sends instructions to") Rel_U(warehouse, customer, "Dispatches goods to") @enduml
为了本书的目的,我们想象业务部门决定实施一种令人兴奋的新的库存分配方式。到目前为止,业务部门一直根据仓库中实际可用的库存和交货时间来展示库存和交货时间。如果仓库缺货,产品将被列为“缺货”,直到下一批货物从制造商处到达。
这是创新之处:如果我们有一个系统可以跟踪我们所有的货物以及它们何时到货,我们可以将这些船上的货物视为真实的库存和我们库存的一部分,只是交货时间稍长。看起来缺货的商品会更少,我们将销售更多,并且企业可以通过减少国内仓库的库存来节省资金。
但是,分配订单不再是简单地减少仓库系统中的单个数量的问题。我们需要更复杂的分配机制。是时候进行一些领域建模了。
探索领域语言
理解领域模型需要时间、耐心和便利贴。我们与我们的领域专家进行初步对话,并就领域模型的第一个最小版本的词汇表和一些规则达成一致。在可能的情况下,我们要求提供具体的示例来说明每个规则。
我们确保用业务术语(DDD 术语中的通用语言)表达这些规则。我们为我们的对象选择易于记忆的标识符,以便更轻松地讨论示例。
以下侧边栏 显示了我们在与领域专家就分配进行对话时可能记录的一些笔记。
单元测试领域模型
我们不会在本书中向您展示 TDD 的工作原理,但我们想向您展示我们将如何从这次业务对话中构建模型。
这是我们的第一个测试可能看起来的样子
def test_allocating_to_a_batch_reduces_the_available_quantity():
batch = Batch("batch-001", "SMALL-TABLE", qty=20, eta=date.today())
line = OrderLine("order-ref", "SMALL-TABLE", 2)
batch.allocate(line)
assert batch.available_quantity == 18我们的单元测试的名称描述了我们希望从系统中看到的行为,并且我们使用的类和变量的名称取自业务术语。我们可以向我们的非技术同事展示此代码,他们会同意这正确地描述了系统的行为。
这是一个满足我们要求的领域模型
@dataclass(frozen=True) #(1) (2)
class OrderLine:
orderid: str
sku: str
qty: int
class Batch:
def __init__(self, ref: str, sku: str, qty: int, eta: Optional[date]): #(2)
self.reference = ref
self.sku = sku
self.eta = eta
self.available_quantity = qty
def allocate(self, line: OrderLine): #(3)
self.available_quantity -= line.qty-
OrderLine是一个不可变的数据类,没有行为。[2] -
为了保持代码清单的简洁,我们没有在大多数代码清单中显示导入。我们希望您可以猜到这是通过
from dataclasses import dataclass导入的;同样,typing.Optional和datetime.date也是如此。如果您想仔细检查任何内容,您可以在每个章节的分支中查看完整的可运行代码(例如,chapter_01_domain_model)。 -
类型提示在 Python 世界中仍然是一个有争议的问题。对于领域模型,它们有时可以帮助阐明或记录预期的参数是什么,并且使用 IDE 的人们通常会对此表示感谢。您可能会认为在可读性方面付出的代价太高。
我们在这里的实现很简单:Batch 只是包装了一个整数 available_quantity,我们在分配时减小该值。我们编写了很多代码只是为了将一个数字减去另一个数字,但我们认为精确地建模我们的领域将会有回报。[3]
让我们编写一些新的失败测试
def make_batch_and_line(sku, batch_qty, line_qty):
return (
Batch("batch-001", sku, batch_qty, eta=date.today()),
OrderLine("order-123", sku, line_qty),
)
def test_can_allocate_if_available_greater_than_required():
large_batch, small_line = make_batch_and_line("ELEGANT-LAMP", 20, 2)
assert large_batch.can_allocate(small_line)
def test_cannot_allocate_if_available_smaller_than_required():
small_batch, large_line = make_batch_and_line("ELEGANT-LAMP", 2, 20)
assert small_batch.can_allocate(large_line) is False
def test_can_allocate_if_available_equal_to_required():
batch, line = make_batch_and_line("ELEGANT-LAMP", 2, 2)
assert batch.can_allocate(line)
def test_cannot_allocate_if_skus_do_not_match():
batch = Batch("batch-001", "UNCOMFORTABLE-CHAIR", 100, eta=None)
different_sku_line = OrderLine("order-123", "EXPENSIVE-TOASTER", 10)
assert batch.can_allocate(different_sku_line) is False这里没有什么太出乎意料的事情。我们重构了我们的测试套件,以便我们不会重复相同的代码行来为相同的 SKU 创建批次和订单项;并且我们为新的方法 can_allocate 编写了四个简单的测试。再次注意,我们使用的名称反映了我们领域专家的语言,并且我们商定的示例直接写入代码。
我们也可以通过编写 Batch 的 can_allocate 方法来直接实现这一点
def can_allocate(self, line: OrderLine) -> bool:
return self.sku == line.sku and self.available_quantity >= line.qty到目前为止,我们可以通过仅递增和递减 Batch.available_quantity 来管理实现,但是当我们进入 deallocate() 测试时,我们将被迫采用更智能的解决方案
def test_can_only_deallocate_allocated_lines():
batch, unallocated_line = make_batch_and_line("DECORATIVE-TRINKET", 20, 2)
batch.deallocate(unallocated_line)
assert batch.available_quantity == 20在此测试中,我们断言从批次中取消分配订单项除非批次先前分配了该订单项,否则无效。为了使此功能正常工作,我们的 Batch 需要了解已分配了哪些订单项。让我们看一下实现
class Batch:
def __init__(self, ref: str, sku: str, qty: int, eta: Optional[date]):
self.reference = ref
self.sku = sku
self.eta = eta
self._purchased_quantity = qty
self._allocations = set() # type: Set[OrderLine]
def allocate(self, line: OrderLine):
if self.can_allocate(line):
self._allocations.add(line)
def deallocate(self, line: OrderLine):
if line in self._allocations:
self._allocations.remove(line)
@property
def allocated_quantity(self) -> int:
return sum(line.qty for line in self._allocations)
@property
def available_quantity(self) -> int:
return self._purchased_quantity - self.allocated_quantity
def can_allocate(self, line: OrderLine) -> bool:
return self.sku == line.sku and self.available_quantity >= line.qty我们在 UML 中的模型 显示了 UML 中的模型。
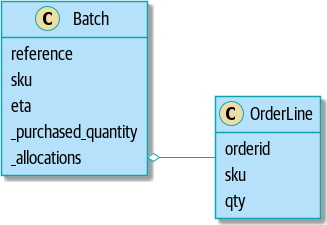
[plantuml, apwp_0103, config=plantuml.cfg]
@startuml
scale 4
left to right direction
hide empty members
class Batch {
reference
sku
eta
_purchased_quantity
_allocations
}
class OrderLine {
orderid
sku
qty
}
Batch::_allocations o-- OrderLine
现在我们有所进展了!一个批次现在跟踪一组已分配的 OrderLine 对象。当我们分配时,如果我们有足够的可用数量,我们只需添加到集合中。我们的 available_quantity 现在是一个计算属性:购买数量减去已分配数量。
是的,我们还可以做很多事情。allocate() 和 deallocate() 都可以静默失败,这有点令人不安,但我们有基本知识了。
顺便说一句,使用集合 ._allocations 使我们能够轻松处理最后一个测试,因为集合中的项目是唯一的
def test_allocation_is_idempotent():
batch, line = make_batch_and_line("ANGULAR-DESK", 20, 2)
batch.allocate(line)
batch.allocate(line)
assert batch.available_quantity == 18目前,说领域模型太微不足道,不值得使用 DDD(甚至面向对象!)可能是一个有效的批评。在现实生活中,会出现许多业务规则和边缘情况:客户可以要求在特定的未来日期交货,这意味着我们可能不想将他们分配到最早的批次。某些 SKU 不在批次中,而是直接从供应商处按需订购,因此它们具有不同的逻辑。根据客户的地理位置,我们可以仅分配给他们所在区域内的部分仓库和发货——除非对于某些 SKU,如果我们本地区域缺货,我们很乐意从不同区域的仓库发货。等等。现实世界中的真实业务知道如何以比我们在页面上展示的速度更快地堆积复杂性!
但是,以这个简单的领域模型作为更复杂事物的占位符,我们将在本书的其余部分扩展我们简单的领域模型,并将其插入到 API、数据库和电子表格的真实世界中。我们将看到,严格遵守我们的封装和谨慎分层原则将如何帮助我们避免代码混乱。
数据类非常适合值对象
我们在之前的代码清单中大量使用了 line,但是 line 是什么?在我们的业务语言中,订单 有多个 订单项,其中每个订单项都有一个 SKU 和一个数量。我们可以想象,包含订单信息的简单 YAML 文件可能如下所示
Order_reference: 12345
Lines:
- sku: RED-CHAIR
qty: 25
- sku: BLU-CHAIR
qty: 25
- sku: GRN-CHAIR
qty: 25请注意,虽然订单有一个唯一标识它的 编号,但 订单项 没有。(即使我们将订单编号添加到 OrderLine 类中,它也不是唯一标识订单项本身的东西。)
每当我们有一个具有数据但没有标识的业务概念时,我们通常选择使用 值对象 模式来表示它。值对象 是任何由其持有的数据唯一标识的领域对象;我们通常使它们不可变
@dataclass(frozen=True)
class OrderLine:
orderid: OrderReference
sku: ProductReference
qty: Quantity数据类(或命名元组)给我们带来的好处之一是 值相等性,这是一种花哨的说法,意思是“具有相同 orderid、sku 和 qty 的两个订单项是相等的。”
from dataclasses import dataclass
from typing import NamedTuple
from collections import namedtuple
@dataclass(frozen=True)
class Name:
first_name: str
surname: str
class Money(NamedTuple):
currency: str
value: int
Line = namedtuple('Line', ['sku', 'qty'])
def test_equality():
assert Money('gbp', 10) == Money('gbp', 10)
assert Name('Harry', 'Percival') != Name('Bob', 'Gregory')
assert Line('RED-CHAIR', 5) == Line('RED-CHAIR', 5)这些值对象符合我们对它们的值如何工作的现实世界的直觉。我们谈论哪个 10 英镑的钞票并不重要,因为它们都具有相同的价值。同样,如果名字和姓氏都匹配,则两个名字是相等的;如果两条订单项具有相同的客户订单、产品代码和数量,则它们是等效的。但是,我们仍然可以在值对象上支持复杂的行为。实际上,支持对值进行操作是很常见的;例如,数学运算符
fiver = Money('gbp', 5)
tenner = Money('gbp', 10)
def can_add_money_values_for_the_same_currency():
assert fiver + fiver == tenner
def can_subtract_money_values():
assert tenner - fiver == fiver
def adding_different_currencies_fails():
with pytest.raises(ValueError):
Money('usd', 10) + Money('gbp', 10)
def can_multiply_money_by_a_number():
assert fiver * 5 == Money('gbp', 25)
def multiplying_two_money_values_is_an_error():
with pytest.raises(TypeError):
tenner * fiver要使这些测试实际通过,您需要开始在我们的 Money 类上实现一些魔术方法
@dataclass(frozen=True)
class Money:
currency: str
value: int
def __add__(self, other) -> Money:
if other.currency != self.currency:
raise ValueError(f"Cannot add {self.currency} to {other.currency}")
return Money(self.currency, self.value + other.value)值对象和实体
订单项由其订单 ID、SKU 和数量唯一标识;如果我们更改其中一个值,我们现在就有了新的订单项。这就是值对象的定义:任何仅由其数据标识且没有长期标识的对象。但是,批次呢?它是由一个编号标识的。
我们使用术语 实体 来描述具有长期标识的领域对象。在上一页中,我们引入了 Name 类作为值对象。如果我们取名字 Harry Percival 并更改一个字母,我们就有了新的 Name 对象 Barry Percival。
应该清楚的是,Harry Percival 不等于 Barry Percival
def test_name_equality():
assert Name("Harry", "Percival") != Name("Barry", "Percival")但是 Harry 作为人呢?人会更改他们的名字、婚姻状况,甚至性别,但我们仍然认为他们是同一个人。那是因为人类与名字不同,具有持久的 标识
class Person:
def __init__(self, name: Name):
self.name = name
def test_barry_is_harry():
harry = Person(Name("Harry", "Percival"))
barry = harry
barry.name = Name("Barry", "Percival")
assert harry is barry and barry is harry实体与值不同,具有 标识相等性。我们可以更改它们的值,并且它们仍然可以识别为同一事物。在我们的示例中,批次是实体。我们可以将订单项分配给批次,或更改我们预计它到达的日期,它仍然是相同的实体。
我们通常通过在实体上实现相等运算符来在代码中显式地做到这一点
class Batch:
...
def __eq__(self, other):
if not isinstance(other, Batch):
return False
return other.reference == self.reference
def __hash__(self):
return hash(self.reference)Python 的 __eq__ 魔术方法定义了类对于 == 运算符的行为。[5]
对于实体和值对象,也值得考虑 __hash__ 将如何工作。它是 Python 用于控制对象行为的魔术方法,当您将它们添加到集合或将它们用作 dict 键时;您可以在 Python 文档 中找到更多信息。
对于值对象,哈希应基于所有值属性,并且我们应确保对象是不可变的。通过在数据类上指定 @frozen=True,我们可以免费获得此功能。
对于实体,最简单的选择是说哈希为 None,这意味着对象不可哈希,例如,不能在集合中使用。如果出于某种原因,您决定确实想对实体使用集合或 dict 操作,则哈希应基于属性(例如 .reference),这些属性定义了实体随时间推移的唯一标识。您还应该尝试以某种方式使该属性为只读。
|
警告
|
这是一个棘手的领域;您不应在不修改 __eq__ 的情况下修改 __hash__。如果您不确定自己在做什么,建议进一步阅读。我们的技术审阅 Hynek Schlawack 的“Python 哈希和相等性” 是一个很好的起点。 |
并非所有内容都必须是对象:领域服务函数
我们已经建立了一个模型来表示批次,但我们实际需要做的是针对代表我们所有库存的一组特定批次分配订单项。
有时,它只是不是一个东西。
领域驱动设计
Evans 讨论了领域服务操作的想法,这些操作在实体或值对象中没有自然的归属。[6] 给定一组批次,分配订单项的东西听起来很像一个函数,我们可以利用 Python 是一种多范式语言的事实,并将其仅作为一个函数。
让我们看看我们如何测试驱动这样的函数
def test_prefers_current_stock_batches_to_shipments():
in_stock_batch = Batch("in-stock-batch", "RETRO-CLOCK", 100, eta=None)
shipment_batch = Batch("shipment-batch", "RETRO-CLOCK", 100, eta=tomorrow)
line = OrderLine("oref", "RETRO-CLOCK", 10)
allocate(line, [in_stock_batch, shipment_batch])
assert in_stock_batch.available_quantity == 90
assert shipment_batch.available_quantity == 100
def test_prefers_earlier_batches():
earliest = Batch("speedy-batch", "MINIMALIST-SPOON", 100, eta=today)
medium = Batch("normal-batch", "MINIMALIST-SPOON", 100, eta=tomorrow)
latest = Batch("slow-batch", "MINIMALIST-SPOON", 100, eta=later)
line = OrderLine("order1", "MINIMALIST-SPOON", 10)
allocate(line, [medium, earliest, latest])
assert earliest.available_quantity == 90
assert medium.available_quantity == 100
assert latest.available_quantity == 100
def test_returns_allocated_batch_ref():
in_stock_batch = Batch("in-stock-batch-ref", "HIGHBROW-POSTER", 100, eta=None)
shipment_batch = Batch("shipment-batch-ref", "HIGHBROW-POSTER", 100, eta=tomorrow)
line = OrderLine("oref", "HIGHBROW-POSTER", 10)
allocation = allocate(line, [in_stock_batch, shipment_batch])
assert allocation == in_stock_batch.reference我们的服务可能如下所示
def allocate(line: OrderLine, batches: List[Batch]) -> str:
batch = next(b for b in sorted(batches) if b.can_allocate(line))
batch.allocate(line)
return batch.referencePython 的魔术方法使我们能够以符合 Python 习惯的方式使用我们的模型
您可能喜欢或不喜欢在前面的代码中使用 next(),但我们非常确定您会同意能够在我们的批次列表中使用 sorted() 是不错的、符合 Python 习惯的。
为了使其工作,我们在我们的领域模型上实现 __gt__
class Batch:
...
def __gt__(self, other):
if self.eta is None:
return False
if other.eta is None:
return True
return self.eta > other.eta太棒了。
异常也可以表达领域概念
我们还有最后一个概念要介绍:异常也可以用于表达领域概念。在与领域专家的对话中,我们了解到订单可能由于我们库存不足而无法分配,我们可以通过使用领域异常来捕获这一点
def test_raises_out_of_stock_exception_if_cannot_allocate():
batch = Batch("batch1", "SMALL-FORK", 10, eta=today)
allocate(OrderLine("order1", "SMALL-FORK", 10), [batch])
with pytest.raises(OutOfStock, match="SMALL-FORK"):
allocate(OrderLine("order2", "SMALL-FORK", 1), [batch])我们不会用实现来过多地让您感到厌烦,但主要要注意的是,我们像命名我们的实体、值对象和服务一样,注意以通用语言命名我们的异常
class OutOfStock(Exception):
pass
def allocate(line: OrderLine, batches: List[Batch]) -> str:
try:
batch = next(
...
except StopIteration:
raise OutOfStock(f"Out of stock for sku {line.sku}")本章末尾的领域模型 是我们最终结果的可视化表示。
现在可能就足够了!我们有一个领域服务,可以用于我们的第一个用例。但首先我们需要一个数据库……