
介绍
为什么我们的设计会出错?
当你听到“混沌”这个词时,你会想到什么?也许你会想到嘈杂的证券交易所,或者你早上凌乱的厨房——一切都混乱不堪。当你想到“秩序”这个词时,也许你会想到一个空旷的房间,宁静而平静。然而,对于科学家来说,混沌的特征是同质性(相同),而秩序的特征是复杂性(差异)。
例如,一个精心照料的花园是一个高度有序的系统。园丁用小径和栅栏定义边界,并划出花坛或菜地。随着时间的推移,花园不断发展,变得更加丰富和茂盛;但如果没有刻意的努力,花园将会变得杂乱无章。杂草和野草会扼杀其他植物,覆盖小径,直到最终每个部分看起来都一样——野生且无人管理。
软件系统也趋向于混沌。当我们刚开始构建一个新系统时,我们怀揣着宏伟的愿景,认为我们的代码将是干净且井然有序的,但随着时间的推移,我们发现它积累了垃圾代码和边缘情况,最终变成了一团混乱的管理器类和 util 模块。我们发现我们原本合理的 layered architecture 像一个过于湿软的 trifle 一样坍塌了。混沌的软件系统的特征是功能上的同质性:API 处理程序具有领域知识并发送电子邮件和执行日志记录;“业务逻辑”类不执行任何计算,但执行 I/O;并且所有内容都耦合在一起,以至于更改系统的任何部分都变得充满危险。这种情况非常普遍,以至于软件工程师对混沌有自己的术语:大泥球反模式 (一个真实的依赖关系图(来源:“企业依赖性:纱线大球”,Alex Papadimoulis))。

|
提示
|
大泥球是软件的自然状态,就像荒野是您花园的自然状态一样。需要能量和方向来防止崩溃。 |
幸运的是,避免创建大泥球的技术并不复杂。
封装和抽象
封装和抽象是我们所有程序员都会本能地使用的工具,即使我们不都使用这些确切的词语。请允许我们在此稍作停留,因为它们是本书反复出现的背景主题。
术语“封装”涵盖了两个密切相关的概念:简化行为和隐藏数据。在本文的讨论中,我们使用的是第一种含义。我们通过识别需要在代码中完成的任务,并将该任务交给定义明确的对象或函数来封装行为。我们将该对象或函数称为抽象。
看一下以下两个 Python 代码片段
import json
from urllib.request import urlopen
from urllib.parse import urlencode
params = dict(q='Sausages', format='json')
handle = urlopen('http://api.duckduckgo.com' + '?' + urlencode(params))
raw_text = handle.read().decode('utf8')
parsed = json.loads(raw_text)
results = parsed['RelatedTopics']
for r in results:
if 'Text' in r:
print(r['FirstURL'] + ' - ' + r['Text'])import requests
params = dict(q='Sausages', format='json')
parsed = requests.get('http://api.duckduckgo.com/', params=params).json()
results = parsed['RelatedTopics']
for r in results:
if 'Text' in r:
print(r['FirstURL'] + ' - ' + r['Text'])两个代码清单都做同样的事情:它们将表单编码的值提交到 URL,以便使用搜索引擎 API。但是第二个更易于阅读和理解,因为它在更高的抽象级别上运行。
我们可以更进一步,通过识别和命名我们希望代码为我们执行的任务,并使用更高层次的抽象使其更明确
import duckduckpy
for r in duckduckpy.query('Sausages').related_topics:
print(r.first_url, ' - ', r.text)通过使用抽象来封装行为是使代码更具表现力、更易于测试和更易于维护的强大工具。
本书中的大多数模式都涉及选择抽象,因此您将在每一章中看到大量的示例。此外,[chapter_03_abstractions] 专门讨论了选择抽象的一些通用启发式方法。
分层
封装和抽象通过隐藏细节和保护数据的完整性来帮助我们,但我们也需要关注对象和函数之间的交互。当一个函数、模块或对象使用另一个时,我们说一个依赖于另一个。这些依赖关系形成一种网络或图。
在大泥球中,依赖关系失控(正如您在一个真实的依赖关系图(来源:“企业依赖性:纱线大球”,Alex Papadimoulis)中所见)。更改图中的一个节点变得困难,因为它有可能影响系统的许多其他部分。分层架构是解决此问题的一种方法。在分层架构中,我们将代码划分为离散的类别或角色,并引入关于哪些类别的代码可以相互调用的规则。
最常见的示例之一是分层架构中所示的三层架构(分层架构)。
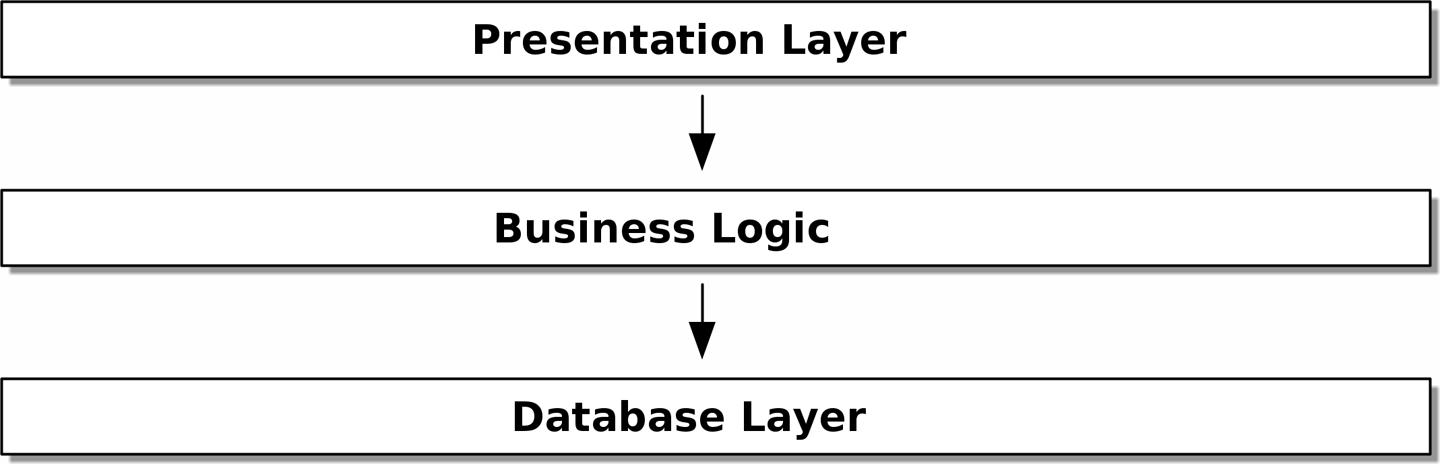
[ditaa, apwp_0002]
+----------------------------------------------------+
| Presentation Layer |
+----------------------------------------------------+
|
V
+----------------------------------------------------+
| Business Logic |
+----------------------------------------------------+
|
V
+----------------------------------------------------+
| Database Layer |
+----------------------------------------------------+
分层架构可能是构建业务软件最常见的模式。在此模型中,我们有用户界面组件,可以是网页、API 或命令行;这些用户界面组件与包含我们的业务规则和工作流程的业务逻辑层通信;最后,我们有一个数据库层,负责存储和检索数据。
在本书的其余部分,我们将通过遵守一个简单的原则,系统地将此模型颠倒过来。
依赖倒置原则
您可能已经熟悉依赖倒置原则 (DIP),因为它就是 SOLID 中的 D。[2]
遗憾的是,我们无法像对封装那样使用三个小的代码清单来说明 DIP。然而,[part1] 的全部内容本质上是在整个应用程序中实现 DIP 的一个工作示例,因此您将获得大量的具体示例。
与此同时,我们可以谈谈 DIP 的正式定义
-
高级模块不应依赖于低级模块。两者都应依赖于抽象。
-
抽象不应依赖于细节。相反,细节应依赖于抽象。
但这意味着什么?让我们一点一点地来看。
高级模块是您的组织真正关心的代码。也许您在一家制药公司工作,您的高级模块处理患者和试验。也许您在一家银行工作,您的高级模块管理交易和兑换。软件系统的高级模块是处理我们现实世界概念的函数、类和包。
相比之下,低级模块是您的组织不关心的代码。您的 HR 部门不太可能对文件系统或网络套接字感到兴奋。您不常与您的财务团队讨论 SMTP、HTTP 或 AMQP。对于我们的非技术利益相关者来说,这些低级概念既不有趣也不相关。他们关心的只是高级概念是否正常工作。如果工资按时发放,您的企业不太可能关心那是 cron 作业还是在 Kubernetes 上运行的瞬态函数。
“依赖于”不一定意味着导入或调用,而是一个更普遍的想法,即一个模块知道或需要另一个模块。
我们已经提到过抽象:它们是封装行为的简化接口,就像我们的 duckduckgo 模块封装了搜索引擎的 API 一样。
计算机科学中的所有问题都可以通过增加一个间接层来解决。
因此,DIP 的第一部分说,我们的业务代码不应依赖于技术细节;相反,两者都应使用抽象。
为什么?广义上讲,因为我们希望能够彼此独立地更改它们。高级模块应该易于更改以响应业务需求。低级模块(细节)在实践中通常更难更改:想想重构以更改函数名称与定义、测试和部署数据库迁移以更改列名称。我们不希望业务逻辑更改因与低级基础设施细节紧密耦合而减慢速度。但是,同样,重要的是能够在需要时更改您的基础设施细节(例如,考虑分片数据库),而无需更改您的业务层。在它们之间添加一个抽象(著名的额外间接层)允许两者(更)独立地相互更改。
第二部分更加神秘。“抽象不应依赖于细节”似乎足够清楚,但“细节应依赖于抽象”很难想象。我们怎么能有一个不依赖于它所抽象的细节的抽象呢?到我们看到 [chapter_04_service_layer] 时,我们将有一个具体的例子,应该使这一切更清晰一些。
我们所有业务逻辑的归宿:领域模型
但在我们能够将三层架构颠倒过来之前,我们需要更多地谈论中间层:高级模块或业务逻辑。我们的设计出错的最常见原因之一是业务逻辑分散在应用程序的各个层中,使得它难以识别、理解和更改。
[chapter_01_domain_model] 展示了如何使用领域模型模式构建业务层。[part1] 中的其余模式展示了我们如何通过选择正确的抽象并持续应用 DIP 来保持领域模型易于更改且不受低级问题的困扰。