
4:我们的第一个用例:Flask API 和服务层
回到我们的分配项目!之前:我们通过与仓库和领域模型对话来驱动我们的应用程序 展示了我们在 [chapter_02_repository] 结尾达到的点,其中涵盖了仓库模式。
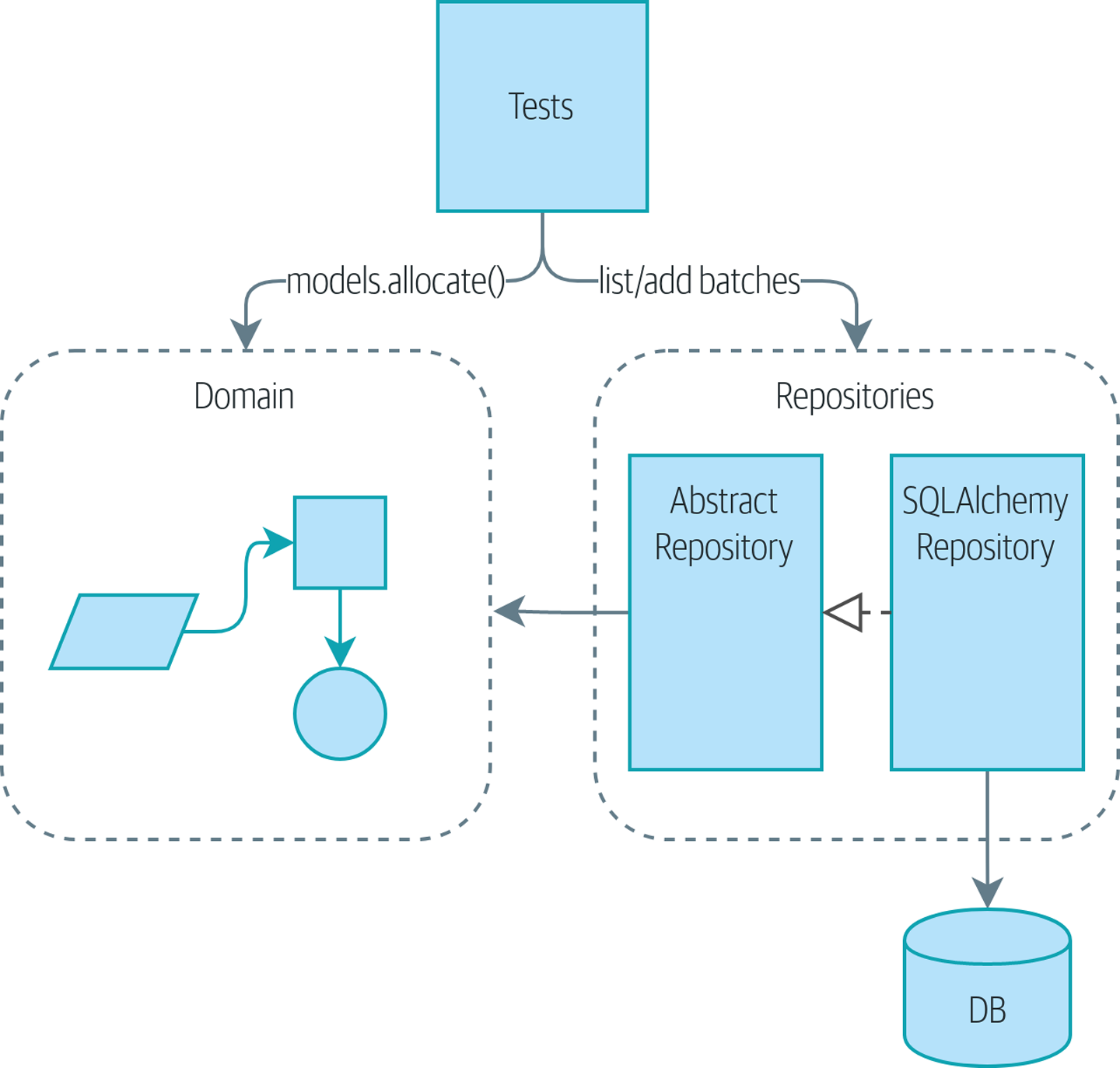
在本章中,我们将讨论编排逻辑、业务逻辑和接口代码之间的区别,并介绍服务层模式,以负责编排我们的工作流程并定义我们系统的用例。
我们还将讨论测试:通过将服务层与我们数据库之上的仓库抽象相结合,我们能够编写快速测试,不仅针对我们的领域模型,而且针对用例的整个工作流程。
服务层将成为进入我们应用程序的主要方式 展示了我们的目标:我们将添加一个 Flask API,它将与服务层对话,服务层将作为我们领域模型的入口点。由于我们的服务层依赖于 AbstractRepository,我们可以通过使用 FakeRepository 对其进行单元测试,但在生产代码中使用 SqlAlchemyRepository 运行。
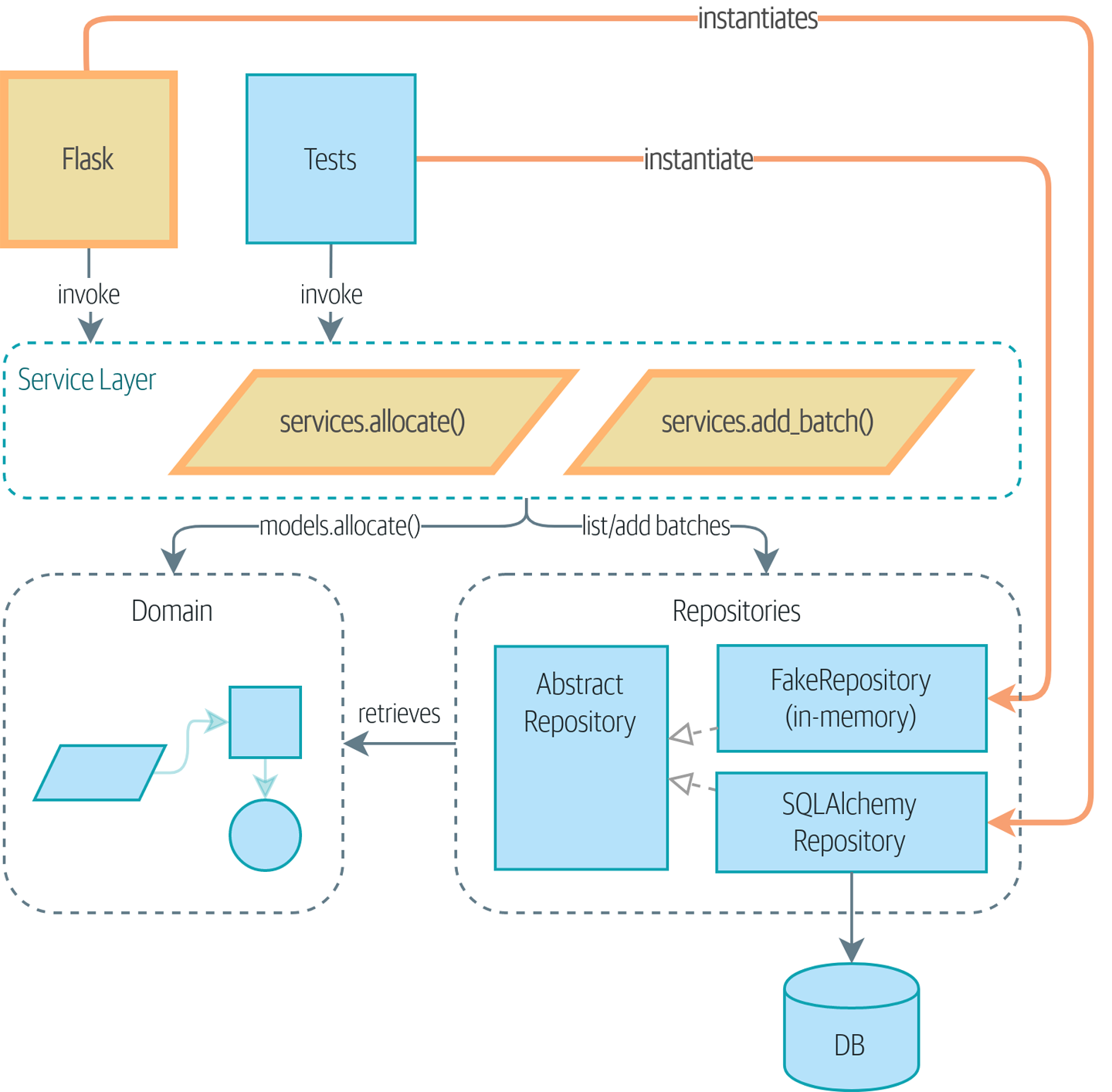
在我们的图表中,我们使用约定,用粗体文本/线条(以及黄色/橙色,如果您正在阅读数字版本)突出显示新组件。
|
提示
|
本章的代码在 chapter_04_service_layer 分支 on GitHub 中 git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_04_service_layer # or to code along, checkout Chapter 2: git checkout chapter_02_repository |
将我们的应用程序连接到真实世界
像任何优秀的敏捷团队一样,我们正在努力尽快推出 MVP 并将其展示给用户,以便开始收集反馈。我们拥有领域模型的核心和分配订单所需的领域服务,以及用于持久存储的仓库接口。
让我们尽快将所有移动部件连接在一起,然后重构为更清晰的架构。这是我们的计划
-
使用 Flask 在我们的
allocate领域服务前面放置一个 API 端点。连接数据库会话和我们的仓库。使用端到端测试和一些快速而肮脏的 SQL 来准备测试数据来测试它。 -
重构出一个服务层,它可以作为抽象来捕获用例,并且将位于 Flask 和我们的领域模型之间。构建一些服务层测试,并展示它们如何使用
FakeRepository。 -
实验我们服务层函数的不同类型的参数;表明使用原始数据类型允许服务层的客户端(我们的测试和我们的 Flask API)与模型层解耦。
第一个端到端测试
没有人有兴趣进行关于什么是端到端 (E2E) 测试与功能测试与验收测试与集成测试与单元测试的长期术语辩论。不同的项目需要不同的测试组合,我们已经看到非常成功的项目只是将事物分为“快速测试”和“慢速测试”。
现在,我们想编写一个或两个将要执行“真实”API 端点(使用 HTTP)并与真实数据库对话的测试。让我们将它们称为端到端测试,因为它是最不言自明的名称之一。
以下显示了第一个版本
@pytest.mark.usefixtures("restart_api")
def test_api_returns_allocation(add_stock):
sku, othersku = random_sku(), random_sku("other") #(1)
earlybatch = random_batchref(1)
laterbatch = random_batchref(2)
otherbatch = random_batchref(3)
add_stock( #(2)
[
(laterbatch, sku, 100, "2011-01-02"),
(earlybatch, sku, 100, "2011-01-01"),
(otherbatch, othersku, 100, None),
]
)
data = {"orderid": random_orderid(), "sku": sku, "qty": 3}
url = config.get_api_url() #(3)
r = requests.post(f"{url}/allocate", json=data)
assert r.status_code == 201
assert r.json()["batchref"] == earlybatch-
random_sku()、random_batchref()等等是使用uuid模块生成随机字符的小助手函数。因为我们现在针对实际数据库运行,所以这是一种防止各种测试和运行相互干扰的方法。 -
add_stock是一个助手 fixture,它只是隐藏了使用 SQL 手动将行插入数据库的细节。我们将在本章后面展示一种更好的方法。 -
config.py 是一个模块,我们在其中保留配置信息。
每个人都以不同的方式解决这些问题,但您将需要某种启动 Flask 的方法,可能在容器中,以及与 Postgres 数据库对话的方法。如果您想了解我们是如何做到的,请查看 [appendix_project_structure]。
直接的实现
以最明显的方式实现事物,您可能会得到类似这样的结果
from flask import Flask, request
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
import config
import model
import orm
import repository
orm.start_mappers()
get_session = sessionmaker(bind=create_engine(config.get_postgres_uri()))
app = Flask(__name__)
@app.route("/allocate", methods=["POST"])
def allocate_endpoint():
session = get_session()
batches = repository.SqlAlchemyRepository(session).list()
line = model.OrderLine(
request.json["orderid"], request.json["sku"], request.json["qty"],
)
batchref = model.allocate(line, batches)
return {"batchref": batchref}, 201到目前为止,一切都很好。鲍勃和哈利,您可能在想,不需要太多您的“架构宇航员”废话。
但是请稍等一下——没有提交。我们实际上并没有将我们的分配保存到数据库中。现在我们需要第二个测试,要么是一个在之后检查数据库状态的测试(不是很黑盒),要么是一个检查如果我们第一次应该已经耗尽批次,我们是否无法分配第二行的测试
@pytest.mark.usefixtures("restart_api")
def test_allocations_are_persisted(add_stock):
sku = random_sku()
batch1, batch2 = random_batchref(1), random_batchref(2)
order1, order2 = random_orderid(1), random_orderid(2)
add_stock(
[(batch1, sku, 10, "2011-01-01"), (batch2, sku, 10, "2011-01-02"),]
)
line1 = {"orderid": order1, "sku": sku, "qty": 10}
line2 = {"orderid": order2, "sku": sku, "qty": 10}
url = config.get_api_url()
# first order uses up all stock in batch 1
r = requests.post(f"{url}/allocate", json=line1)
assert r.status_code == 201
assert r.json()["batchref"] == batch1
# second order should go to batch 2
r = requests.post(f"{url}/allocate", json=line2)
assert r.status_code == 201
assert r.json()["batchref"] == batch2不是那么可爱,但这将迫使我们添加提交。
需要数据库检查的错误条件
但是,如果我们继续这样下去,事情将会变得越来越糟糕。
假设我们想添加一些错误处理。如果域引发错误,对于缺货的 SKU 怎么办?或者 SKU 甚至不存在怎么办?这不是域甚至知道的事情,也不应该知道。这更像是一个健全性检查,我们应该在数据库层实现,甚至在我们调用域服务之前。
现在我们正在查看另外两个端到端测试
@pytest.mark.usefixtures("restart_api")
def test_400_message_for_out_of_stock(add_stock): #(1)
sku, small_batch, large_order = random_sku(), random_batchref(), random_orderid()
add_stock(
[(small_batch, sku, 10, "2011-01-01"),]
)
data = {"orderid": large_order, "sku": sku, "qty": 20}
url = config.get_api_url()
r = requests.post(f"{url}/allocate", json=data)
assert r.status_code == 400
assert r.json()["message"] == f"Out of stock for sku {sku}"
@pytest.mark.usefixtures("restart_api")
def test_400_message_for_invalid_sku(): #(2)
unknown_sku, orderid = random_sku(), random_orderid()
data = {"orderid": orderid, "sku": unknown_sku, "qty": 20}
url = config.get_api_url()
r = requests.post(f"{url}/allocate", json=data)
assert r.status_code == 400
assert r.json()["message"] == f"Invalid sku {unknown_sku}"-
在第一个测试中,我们试图分配比我们库存更多的单位。
-
在第二个测试中,SKU 根本不存在(因为我们从未调用
add_stock),因此就我们的应用程序而言,它是无效的。
当然,我们也可以在 Flask 应用程序中实现它
def is_valid_sku(sku, batches):
return sku in {b.sku for b in batches}
@app.route("/allocate", methods=["POST"])
def allocate_endpoint():
session = get_session()
batches = repository.SqlAlchemyRepository(session).list()
line = model.OrderLine(
request.json["orderid"], request.json["sku"], request.json["qty"],
)
if not is_valid_sku(line.sku, batches):
return {"message": f"Invalid sku {line.sku}"}, 400
try:
batchref = model.allocate(line, batches)
except model.OutOfStock as e:
return {"message": str(e)}, 400
session.commit()
return {"batchref": batchref}, 201但是我们的 Flask 应用程序开始看起来有点笨拙。并且我们的 E2E 测试数量开始失控,很快我们最终会得到一个倒置的测试金字塔(或鲍勃喜欢称之为“冰淇淋锥模型”)。
引入服务层,并使用 FakeRepository 对其进行单元测试
如果我们看看我们的 Flask 应用程序正在做什么,我们会发现很多我们可以称之为编排的东西——从我们的仓库中获取东西,根据数据库状态验证我们的输入,处理错误,并在 happy path 中提交。这些事情中的大多数与拥有 Web API 端点无关(例如,如果您正在构建 CLI,您将需要它们;请参阅 [appendix_csvs]),并且它们实际上不是需要通过端到端测试来测试的东西。
拆分出一个服务层,有时称为编排层或用例层,通常是有意义的。
您还记得我们在 [chapter_03_abstractions] 中准备的 FakeRepository 吗?
class FakeRepository(repository.AbstractRepository):
def __init__(self, batches):
self._batches = set(batches)
def add(self, batch):
self._batches.add(batch)
def get(self, reference):
return next(b for b in self._batches if b.reference == reference)
def list(self):
return list(self._batches)这就是它将派上用场的地方;它让我们使用好的、快速的单元测试来测试我们的服务层
def test_returns_allocation():
line = model.OrderLine("o1", "COMPLICATED-LAMP", 10)
batch = model.Batch("b1", "COMPLICATED-LAMP", 100, eta=None)
repo = FakeRepository([batch]) #(1)
result = services.allocate(line, repo, FakeSession()) #(2) (3)
assert result == "b1"
def test_error_for_invalid_sku():
line = model.OrderLine("o1", "NONEXISTENTSKU", 10)
batch = model.Batch("b1", "AREALSKU", 100, eta=None)
repo = FakeRepository([batch]) #(1)
with pytest.raises(services.InvalidSku, match="Invalid sku NONEXISTENTSKU"):
services.allocate(line, repo, FakeSession()) #(2) (3)-
FakeRepository保存Batch对象,这些对象将由我们的测试使用。 -
我们的 services 模块 (services.py) 将定义一个
allocate()服务层函数。它将位于 API 层中的allocate_endpoint()函数和我们领域模型中的allocate()域服务函数之间。[1] -
我们还需要一个
FakeSession来模拟数据库会话,如下面的代码片段所示。
class FakeSession:
committed = False
def commit(self):
self.committed = True这个假会话只是一个临时的解决方案。我们将在 [chapter_06_uow] 中摆脱它,并使事情变得更加美好。但在同时,假的 .commit() 让我们从 E2E 层迁移第三个测试
def test_commits():
line = model.OrderLine("o1", "OMINOUS-MIRROR", 10)
batch = model.Batch("b1", "OMINOUS-MIRROR", 100, eta=None)
repo = FakeRepository([batch])
session = FakeSession()
services.allocate(line, repo, session)
assert session.committed is True典型的服务函数
我们将编写一个看起来像这样的服务函数
class InvalidSku(Exception):
pass
def is_valid_sku(sku, batches):
return sku in {b.sku for b in batches}
def allocate(line: OrderLine, repo: AbstractRepository, session) -> str:
batches = repo.list() #(1)
if not is_valid_sku(line.sku, batches): #(2)
raise InvalidSku(f"Invalid sku {line.sku}")
batchref = model.allocate(line, batches) #(3)
session.commit() #(4)
return batchref典型的服务层函数具有类似的步骤
-
我们从仓库中获取一些对象。
-
我们针对世界的当前状态对请求进行一些检查或断言。
-
我们调用一个域服务。
-
如果一切顺利,我们保存/更新我们已更改的任何状态。
最后一步目前有点令人不满意,因为我们的服务层与我们的数据库层紧密耦合。我们将在 [chapter_06_uow] 中使用工作单元模式改进这一点。
但是服务层的基本要素已经存在,我们的 Flask 应用程序现在看起来更简洁了
@app.route("/allocate", methods=["POST"])
def allocate_endpoint():
session = get_session() #(1)
repo = repository.SqlAlchemyRepository(session) #(1)
line = model.OrderLine(
request.json["orderid"], request.json["sku"], request.json["qty"], #(2)
)
try:
batchref = services.allocate(line, repo, session) #(2)
except (model.OutOfStock, services.InvalidSku) as e:
return {"message": str(e)}, 400 #(3)
return {"batchref": batchref}, 201 #(3)-
我们实例化一个数据库会话和一些仓库对象。
-
我们从 Web 请求中提取用户的命令,并将它们传递给服务层。
-
我们返回一些带有适当状态代码的 JSON 响应。
Flask 应用程序的职责只是标准的 Web 工作:每个请求的会话管理、解析 POST 参数中的信息、响应状态代码和 JSON。所有的编排逻辑都在用例/服务层中,而领域逻辑保留在域中。
最后,我们可以自信地将我们的 E2E 测试缩减为只有两个,一个用于 happy path,一个用于 unhappy path
@pytest.mark.usefixtures("restart_api")
def test_happy_path_returns_201_and_allocated_batch(add_stock):
sku, othersku = random_sku(), random_sku("other")
earlybatch = random_batchref(1)
laterbatch = random_batchref(2)
otherbatch = random_batchref(3)
add_stock(
[
(laterbatch, sku, 100, "2011-01-02"),
(earlybatch, sku, 100, "2011-01-01"),
(otherbatch, othersku, 100, None),
]
)
data = {"orderid": random_orderid(), "sku": sku, "qty": 3}
url = config.get_api_url()
r = requests.post(f"{url}/allocate", json=data)
assert r.status_code == 201
assert r.json()["batchref"] == earlybatch
@pytest.mark.usefixtures("restart_api")
def test_unhappy_path_returns_400_and_error_message():
unknown_sku, orderid = random_sku(), random_orderid()
data = {"orderid": orderid, "sku": unknown_sku, "qty": 20}
url = config.get_api_url()
r = requests.post(f"{url}/allocate", json=data)
assert r.status_code == 400
assert r.json()["message"] == f"Invalid sku {unknown_sku}"我们已成功将我们的测试分为两个大的类别:关于 Web 内容的测试,我们端到端实现;以及关于编排内容的测试,我们可以在内存中针对服务层进行测试。
为什么一切都称为服务?
你们中的一些人可能此时正在挠头,试图弄清楚领域服务和服务层之间的确切区别是什么。
我们很抱歉——我们没有选择这些名称,否则我们将有更酷更友好的方式来谈论这些东西。
我们在本章中使用了两个称为服务的东西。第一个是应用服务(我们的服务层)。它的工作是处理来自外部世界的请求并编排操作。我们的意思是服务层通过遵循一系列简单的步骤来驱动应用程序
-
从数据库获取一些数据
-
更新领域模型
-
持久化任何更改
这是系统中每个操作都必须发生的枯燥工作,并且将其与业务逻辑分开有助于保持事物整洁。
第二种类型的服务是领域服务。这是指属于领域模型但不自然地位于有状态实体或值对象内的逻辑片段的名称。例如,如果您正在构建一个购物车应用程序,您可能会选择将税收规则构建为领域服务。计算税款是与更新购物车不同的工作,它是模型的重要组成部分,但为这项工作设置持久实体似乎是不合适的。相反,无状态的 TaxCalculator 类或 calculate_tax 函数可以完成这项工作。
将事物放入文件夹以查看它们都属于哪里
随着我们的应用程序变得更大,我们将需要不断整理我们的目录结构。我们项目的布局为我们提供了关于我们将在每个文件中找到哪种对象的有用提示。
这是我们可以组织事物的一种方式
.
├── config.py
├── domain #(1)
│ ├── __init__.py
│ └── model.py
├── service_layer #(2)
│ ├── __init__.py
│ └── services.py
├── adapters #(3)
│ ├── __init__.py
│ ├── orm.py
│ └── repository.py
├── entrypoints (4)
│ ├── __init__.py
│ └── flask_app.py
└── tests
├── __init__.py
├── conftest.py
├── unit
│ ├── test_allocate.py
│ ├── test_batches.py
│ └── test_services.py
├── integration
│ ├── test_orm.py
│ └── test_repository.py
└── e2e
└── test_api.py-
让我们为我们的领域模型创建一个文件夹。目前这只是一个文件,但对于更复杂的应用程序,您可能每个类都有一个文件;您可能为
Entity、ValueObject和Aggregate提供了助手父类,并且您可能会添加一个 exceptions.py 用于领域层异常,并且正如您将在 [part2] 中看到的那样,commands.py 和 events.py。 -
我们将区分服务层。目前这只是一个名为 services.py 的文件,用于我们的服务层函数。您可以在此处添加服务层异常,并且正如您将在 [chapter_05_high_gear_low_gear] 中看到的那样,我们将添加 unit_of_work.py。
-
Adapters 是对端口和适配器术语的致敬。这将填充围绕外部 I/O 的任何其他抽象(例如,redis_client.py)。严格来说,您会称这些为二级适配器或驱动适配器,或者有时是面向内部的适配器。
-
入口点是我们从中驱动应用程序的地方。在官方的端口和适配器术语中,这些也是适配器,被称为一级、驱动或面向外部的适配器。
端口呢?正如您可能记得的那样,它们是适配器实现的抽象接口。我们倾向于将它们与实现它们的适配器放在同一个文件中。
总结
添加服务层确实为我们带来了很多好处
-
我们的 Flask API 端点变得非常简洁且易于编写:它们的唯一职责是执行“Web 工作”,例如解析 JSON 和为 happy 或 unhappy 情况生成正确的 HTTP 代码。
-
我们为我们的域定义了一个清晰的 API,一组用例或入口点,任何适配器都可以使用它们,而无需了解我们的域模型类——无论是 API、CLI(请参阅 [appendix_csvs])还是测试!它们也是我们域的适配器。
-
我们可以通过使用服务层来编写“高速”测试,使我们可以自由地以我们认为合适的任何方式重构领域模型。只要我们仍然可以交付相同的用例,我们就可以尝试新的设计,而无需重写大量的测试。
-
我们的测试金字塔看起来不错——我们的大部分测试都是快速单元测试,只有最少的 E2E 和集成测试。
DIP 的实际应用
服务层的抽象依赖关系 显示了我们服务层的依赖关系:领域模型和 AbstractRepository(端口和适配器术语中的端口)。
当我们运行测试时,测试提供抽象依赖关系的实现 显示了我们如何通过使用 FakeRepository(适配器)来实现抽象依赖关系。
当我们实际运行我们的应用程序时,我们交换到 运行时依赖关系 中显示的“真实”依赖关系。
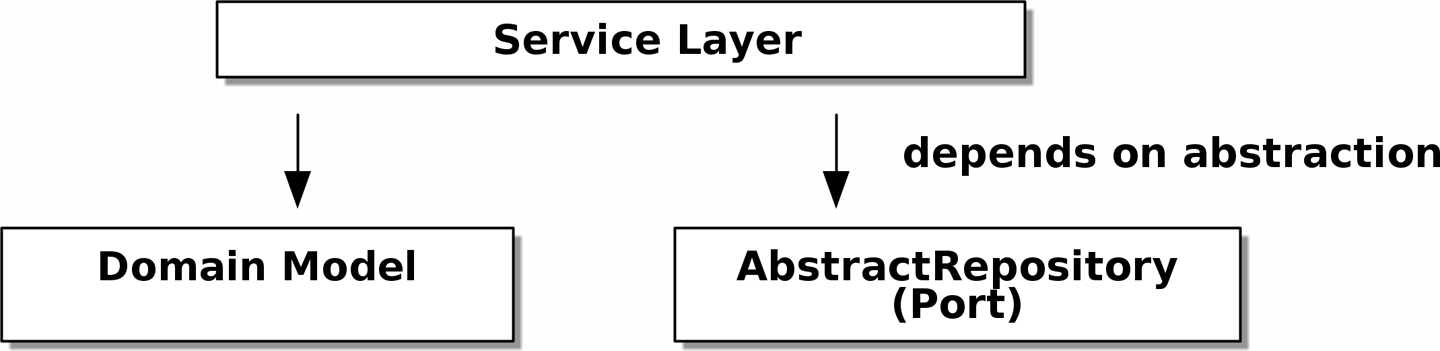
[ditaa, apwp_0403]
+-----------------------------+
| Service Layer |
+-----------------------------+
| |
| | depends on abstraction
V V
+------------------+ +--------------------+
| Domain Model | | AbstractRepository |
| | | (Port) |
+------------------+ +--------------------+
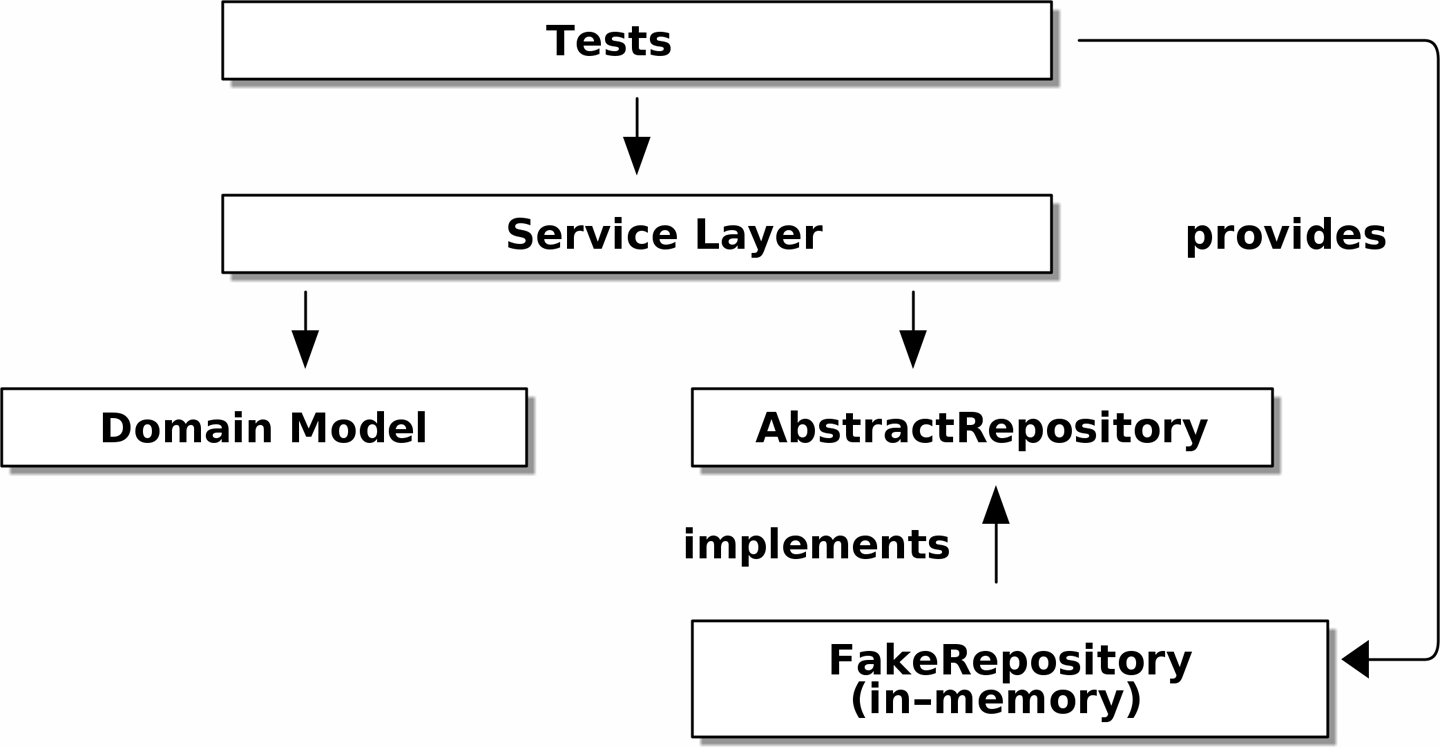
[ditaa, apwp_0404]
+-----------------------------+
| Tests |-------------\
+-----------------------------+ |
| |
V |
+-----------------------------+ |
| Service Layer | provides |
+-----------------------------+ |
| | |
V V |
+------------------+ +--------------------+ |
| Domain Model | | AbstractRepository | |
+------------------+ +--------------------+ |
^ |
implements | |
| |
+----------------------+ |
| FakeRepository |<--/
| (in–memory) |
+----------------------+
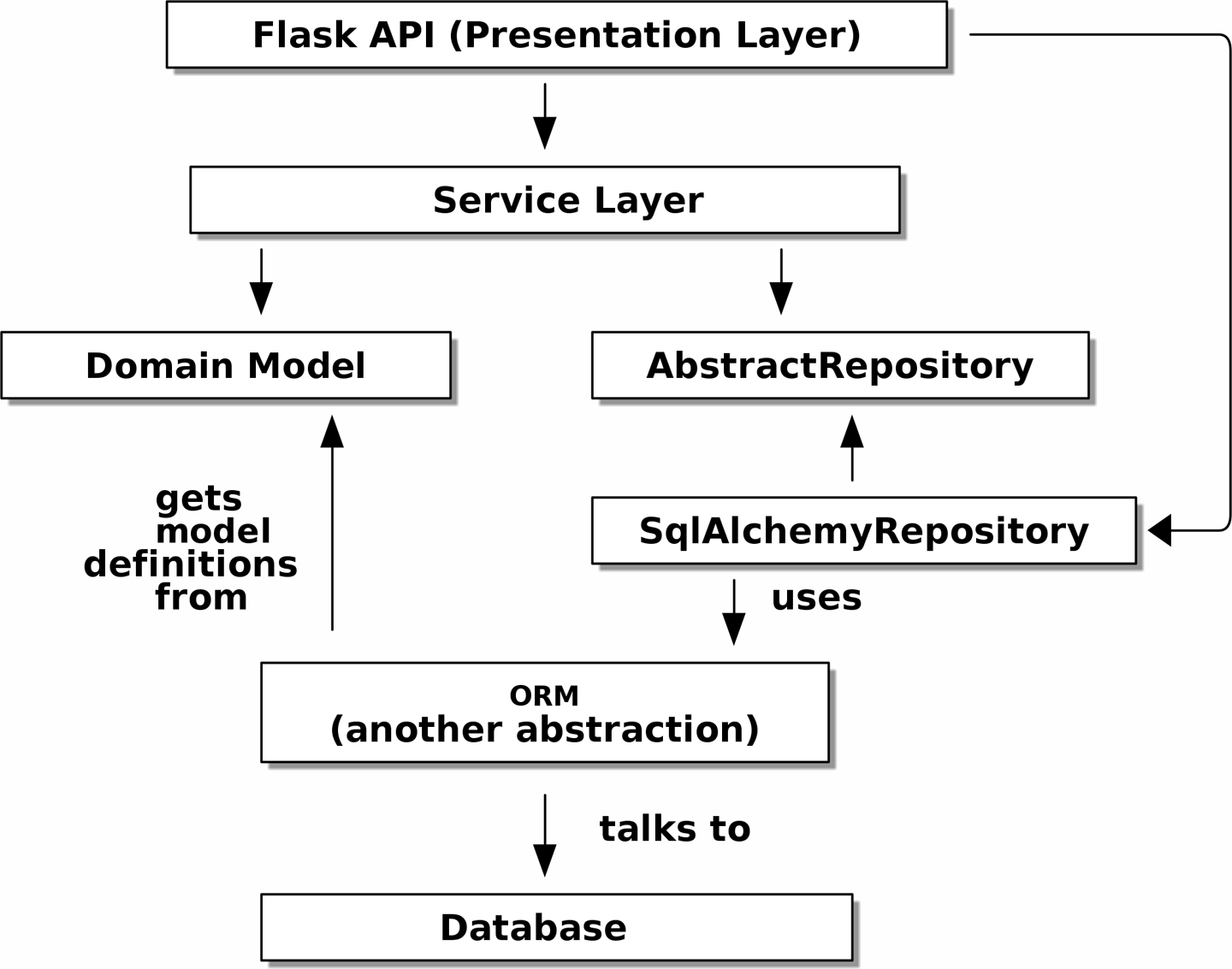
[ditaa, apwp_0405]
+--------------------------------+
| Flask API (Presentation Layer) |-----------\
+--------------------------------+ |
| |
V |
+-----------------------------+ |
| Service Layer | |
+-----------------------------+ |
| | |
V V |
+------------------+ +--------------------+ |
| Domain Model | | AbstractRepository | |
+------------------+ +--------------------+ |
^ ^ |
| | |
gets | +----------------------+ |
model | | SqlAlchemyRepository |<--/
definitions| +----------------------+
from | | uses
| V
+-----------------------+
| ORM |
| (another abstraction) |
+-----------------------+
|
| talks to
V
+------------------------+
| Database |
+------------------------+
太棒了。
让我们暂停一下,查看 服务层:权衡,我们在其中考虑了拥有服务层的所有利弊。
| 优点 | 缺点 |
|---|---|
|
|
但是仍然有一些笨拙之处需要整理
-
服务层仍然与域紧密耦合,因为它的 API 是用
OrderLine对象表示的。在 [chapter_05_high_gear_low_gear] 中,我们将解决这个问题,并讨论服务层如何实现更高效的 TDD。 -
服务层与
session对象紧密耦合。在 [chapter_06_uow] 中,我们将引入另一个与仓库和服务层模式紧密配合的模式,工作单元模式,一切都将非常美好。您会看到的!