
3: 短暂的题外话:关于耦合与抽象
尊敬的读者,请允许我们简要地离题讨论一下抽象这个主题。我们已经多次谈到抽象。例如,仓库模式是持久存储的抽象。但是,是什么构成了一个好的抽象?我们对抽象有什么期望?它们与测试有什么关系?
|
提示
|
本章的代码位于 chapter_03_abstractions 分支 GitHub 上 git clone https://github.com/cosmicpython/code.git git checkout chapter_03_abstractions |
本书的一个关键主题,隐藏在各种花哨的模式之下,是我们如何使用简单的抽象来隐藏混乱的细节。当我们为了乐趣或在 kata[1] 中编写代码时,我们可以自由地玩弄想法,快速完成并积极重构。但在大型系统中,我们受到系统中其他地方做出的决策的约束。
当我们因为害怕破坏组件 B 而无法更改组件 A 时,我们说这些组件已经变得耦合。在局部,耦合是一件好事:它表明我们的代码协同工作,每个组件都支持其他组件,所有组件都像手表的齿轮一样各就各位。在行话中,我们说当耦合元素之间具有高内聚时,这种方式是有效的。
在全球范围内,耦合是一种麻烦:它增加了更改代码的风险和成本,有时甚至让我们感到无法进行任何更改。这就是泥球模式的问题:随着应用程序的增长,如果我们无法阻止没有内聚的元素之间的耦合,那么这种耦合会超线性地增长,直到我们再也无法有效地更改我们的系统。
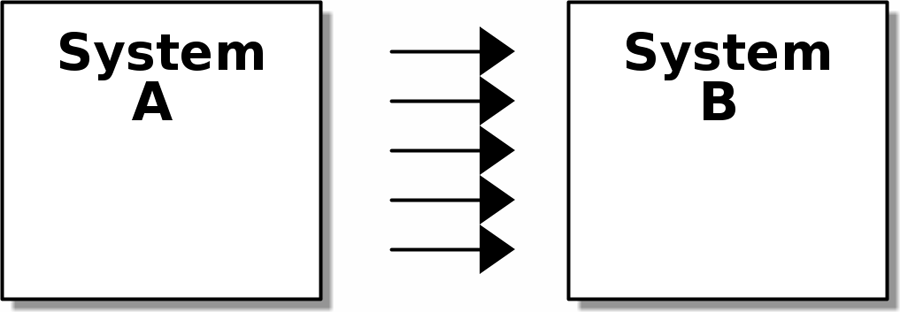
[ditaa, apwp_0301] +--------+ +--------+ | System | ---> | System | | A | ---> | B | | | ---> | | | | ---> | | | | ---> | | +--------+ +--------+

[ditaa, apwp_0302] +--------+ +--------+ | System | /-------------\ | System | | A | ---> | | ---> | B | | | ---> | Abstraction | ---> | | | | | | ---> | | | | \-------------/ | | +--------+ +--------+
在两个图中,我们都有一对子系统,其中一个依赖于另一个。在较高的耦合中,两者之间存在高度耦合;箭头的数量表示两者之间存在多种依赖关系。如果我们需要更改系统 B,则更改很可能波及到系统 A。
然而,在较低的耦合中,我们通过插入一个新的、更简单的抽象来降低了耦合程度。因为它更简单,所以系统 A 对抽象的依赖种类更少。抽象通过隐藏系统 B 所做的任何复杂细节来保护我们免受更改的影响——我们可以更改右侧的箭头,而无需更改左侧的箭头。
抽象状态有助于可测试性
让我们看一个例子。假设我们要编写代码来同步两个文件目录,我们将其称为源目录和目标目录
-
如果源目录中存在某个文件,但目标目录中不存在,则将该文件复制过去。
-
如果源目录中存在某个文件,但其名称与目标目录中的名称不同,则重命名目标文件以匹配。
-
如果目标目录中存在某个文件,但源目录中不存在,则将其删除。
我们的第一个和第三个要求很简单:我们可以直接比较两个路径列表。但是,我们的第二个要求比较棘手。为了检测重命名,我们必须检查文件的内容。为此,我们可以使用哈希函数,如 MD5 或 SHA-1。从文件生成 SHA-1 哈希的代码非常简单
BLOCKSIZE = 65536
def hash_file(path):
hasher = hashlib.sha1()
with path.open("rb") as file:
buf = file.read(BLOCKSIZE)
while buf:
hasher.update(buf)
buf = file.read(BLOCKSIZE)
return hasher.hexdigest()现在我们需要编写做出决策的部分——业务逻辑,如果你愿意这么称呼它的话。
当我们必须从第一原理开始解决问题时,我们通常会尝试编写一个简单的实现,然后再重构为更好的设计。我们将在本书中始终使用这种方法,因为它正是我们在现实世界中编写代码的方式:从解决问题的最小部分开始,然后迭代地使解决方案更丰富、设计更好。
我们的第一个粗略方法看起来像这样
import hashlib
import os
import shutil
from pathlib import Path
def sync(source, dest):
# Walk the source folder and build a dict of filenames and their hashes
source_hashes = {}
for folder, _, files in os.walk(source):
for fn in files:
source_hashes[hash_file(Path(folder) / fn)] = fn
seen = set() # Keep track of the files we've found in the target
# Walk the target folder and get the filenames and hashes
for folder, _, files in os.walk(dest):
for fn in files:
dest_path = Path(folder) / fn
dest_hash = hash_file(dest_path)
seen.add(dest_hash)
# if there's a file in target that's not in source, delete it
if dest_hash not in source_hashes:
dest_path.remove()
# if there's a file in target that has a different path in source,
# move it to the correct path
elif dest_hash in source_hashes and fn != source_hashes[dest_hash]:
shutil.move(dest_path, Path(folder) / source_hashes[dest_hash])
# for every file that appears in source but not target, copy the file to
# the target
for source_hash, fn in source_hashes.items():
if source_hash not in seen:
shutil.copy(Path(source) / fn, Path(dest) / fn)太棒了!我们有一些代码,它看起来还可以,但在我们的硬盘上运行它之前,也许我们应该对其进行测试。我们如何进行这种测试呢?
def test_when_a_file_exists_in_the_source_but_not_the_destination():
try:
source = tempfile.mkdtemp()
dest = tempfile.mkdtemp()
content = "I am a very useful file"
(Path(source) / "my-file").write_text(content)
sync(source, dest)
expected_path = Path(dest) / "my-file"
assert expected_path.exists()
assert expected_path.read_text() == content
finally:
shutil.rmtree(source)
shutil.rmtree(dest)
def test_when_a_file_has_been_renamed_in_the_source():
try:
source = tempfile.mkdtemp()
dest = tempfile.mkdtemp()
content = "I am a file that was renamed"
source_path = Path(source) / "source-filename"
old_dest_path = Path(dest) / "dest-filename"
expected_dest_path = Path(dest) / "source-filename"
source_path.write_text(content)
old_dest_path.write_text(content)
sync(source, dest)
assert old_dest_path.exists() is False
assert expected_dest_path.read_text() == content
finally:
shutil.rmtree(source)
shutil.rmtree(dest)哇哦,这两个简单的案例需要大量的设置!问题在于,我们的领域逻辑“找出两个目录之间的差异”与 I/O 代码紧密耦合。如果不调用 pathlib、shutil 和 hashlib 模块,我们就无法运行我们的差异算法。
麻烦的是,即使对于我们当前的要求,我们也没有编写足够的测试:当前的实现存在多个错误(例如,shutil.move() 是错误的)。获得良好的覆盖率并揭示这些错误意味着编写更多的测试,但如果它们都像前面的那些一样笨拙,那将会变得非常痛苦。
最重要的是,我们的代码的可扩展性不高。想象一下尝试实现一个 --dry-run 标志,让我们的代码只打印出它将要做的事情,而不是实际执行它。或者,如果我们想同步到远程服务器或云存储怎么办?
我们的高层代码与底层细节耦合在一起,这让生活变得艰难。随着我们考虑的场景变得更加复杂,我们的测试将变得更加笨拙。我们当然可以重构这些测试(例如,一些清理工作可以放入 pytest fixtures 中),但只要我们进行文件系统操作,它们就会保持缓慢,并且难以阅读和编写。
选择正确的抽象
我们应该怎么做才能重写我们的代码,使其更具可测试性?
首先,我们需要考虑我们的代码需要文件系统的哪些内容。通读代码,我们可以看到正在发生三件不同的事情。我们可以将这些视为代码具有的三个不同的职责
-
我们使用
os.walk查询文件系统,并确定一系列路径的哈希值。这在源目录和目标目录的情况下都是相似的。 -
我们决定文件是新的、已重命名的还是冗余的。
-
我们复制、移动或删除文件以匹配源目录。
请记住,我们希望为每个职责找到简化的抽象。这将使我们能够隐藏混乱的细节,以便我们可以专注于有趣的逻辑。[2]
|
注意
|
在本章中,我们将一些棘手的代码重构为更具可测试性的结构,方法是识别需要完成的独立任务,并将每个任务分配给明确定义的参与者,这与 duckduckgo 示例类似。 |
对于步骤 1 和 2,我们已经直观地开始使用抽象,即哈希到路径的字典。您可能已经想过,“为什么不为目标文件夹以及源文件夹构建一个字典,然后我们只需比较两个字典?” 这似乎是抽象文件系统当前状态的一种好方法
source_files = {'hash1': 'path1', 'hash2': 'path2'}
dest_files = {'hash1': 'path1', 'hash2': 'pathX'}
从步骤 2 到步骤 3 呢?我们如何抽象出实际的移动/复制/删除文件系统交互?
我们将在这里应用一个技巧,我们将在本书的后面大规模地使用它。我们将把我们想做什么与如何做它分开。我们将使我们的程序输出一个命令列表,如下所示
("COPY", "sourcepath", "destpath"),
("MOVE", "old", "new"),
现在我们可以编写仅使用两个文件系统字典作为输入的测试,并且我们期望输出表示操作的字符串元组列表。
我们不是说“给定这个实际的文件系统,当我运行我的函数时,检查发生了什么操作”,而是说“给定文件系统的这个抽象,将发生文件系统操作的什么抽象?”
def test_when_a_file_exists_in_the_source_but_not_the_destination():
source_hashes = {'hash1': 'fn1'}
dest_hashes = {}
expected_actions = [('COPY', '/src/fn1', '/dst/fn1')]
...
def test_when_a_file_has_been_renamed_in_the_source():
source_hashes = {'hash1': 'fn1'}
dest_hashes = {'hash1': 'fn2'}
expected_actions == [('MOVE', '/dst/fn2', '/dst/fn1')]
...实现我们选择的抽象
这一切都很好,但是我们实际上如何编写这些新测试,以及我们如何更改我们的实现以使其全部工作?
我们的目标是隔离我们系统的聪明部分,并能够在不需要设置真实文件系统的情况下彻底测试它。我们将创建一个没有外部状态依赖项的代码“核心”,然后查看当我们给它来自外部世界的输入时,它会如何响应(这种方法被 Gary Bernhardt 描述为 Functional Core, Imperative Shell,或 FCIS)。
让我们首先拆分代码,将有状态的部分与逻辑部分分开。
我们的顶层函数几乎不包含任何逻辑;它只是一个命令式步骤序列:收集输入,调用我们的逻辑,应用输出
def sync(source, dest):
# imperative shell step 1, gather inputs
source_hashes = read_paths_and_hashes(source) #(1)
dest_hashes = read_paths_and_hashes(dest) #(1)
# step 2: call functional core
actions = determine_actions(source_hashes, dest_hashes, source, dest) #(2)
# imperative shell step 3, apply outputs
for action, *paths in actions:
if action == "COPY":
shutil.copyfile(*paths)
if action == "MOVE":
shutil.move(*paths)
if action == "DELETE":
os.remove(paths[0])-
这是我们分解出的第一个函数
read_paths_and_hashes(),它隔离了我们应用程序的 I/O 部分。 -
这是我们雕刻出功能核心、业务逻辑的地方。
现在,构建路径和哈希字典的代码非常容易编写
def read_paths_and_hashes(root):
hashes = {}
for folder, _, files in os.walk(root):
for fn in files:
hashes[hash_file(Path(folder) / fn)] = fn
return hashesdetermine_actions() 函数将是我们业务逻辑的核心,它说:“给定这两组哈希和文件名,我们应该复制/移动/删除什么?” 它接受简单的数据结构并返回简单的数据结构
def determine_actions(source_hashes, dest_hashes, source_folder, dest_folder):
for sha, filename in source_hashes.items():
if sha not in dest_hashes:
sourcepath = Path(source_folder) / filename
destpath = Path(dest_folder) / filename
yield "COPY", sourcepath, destpath
elif dest_hashes[sha] != filename:
olddestpath = Path(dest_folder) / dest_hashes[sha]
newdestpath = Path(dest_folder) / filename
yield "MOVE", olddestpath, newdestpath
for sha, filename in dest_hashes.items():
if sha not in source_hashes:
yield "DELETE", dest_folder / filename我们的测试现在直接作用于 determine_actions() 函数
def test_when_a_file_exists_in_the_source_but_not_the_destination():
source_hashes = {"hash1": "fn1"}
dest_hashes = {}
actions = determine_actions(source_hashes, dest_hashes, Path("/src"), Path("/dst"))
assert list(actions) == [("COPY", Path("/src/fn1"), Path("/dst/fn1"))]
def test_when_a_file_has_been_renamed_in_the_source():
source_hashes = {"hash1": "fn1"}
dest_hashes = {"hash1": "fn2"}
actions = determine_actions(source_hashes, dest_hashes, Path("/src"), Path("/dst"))
assert list(actions) == [("MOVE", Path("/dst/fn2"), Path("/dst/fn1"))]因为我们已经将程序的逻辑(用于识别更改的代码)与低级 I/O 细节解耦,所以我们可以轻松地测试我们代码的核心。
通过这种方法,我们已经从测试我们的主入口点函数 sync() 切换到测试较低级别的函数 determine_actions()。您可能会认为这很好,因为 sync() 现在非常简单。或者您可能会决定保留一些集成/验收测试来测试 sync()。但还有另一种选择,即修改 sync() 函数,使其可以进行单元测试和端到端测试;Bob 称之为边缘到边缘测试的方法。
使用伪造对象和依赖注入进行边缘到边缘测试
当我们开始编写新系统时,我们通常首先关注核心逻辑,并使用直接单元测试来驱动它。但是,在某个时候,我们希望一起测试系统中更大的块。
我们可以回到我们的端到端测试,但这些测试仍然像以前一样难以编写和维护。相反,我们经常编写调用整个系统但伪造 I/O 的测试,有点像边缘到边缘
def sync(source, dest, filesystem=FileSystem()): #(1)
source_hashes = filesystem.read(source) #(2)
dest_hashes = filesystem.read(dest) #(2)
for sha, filename in source_hashes.items():
if sha not in dest_hashes:
sourcepath = Path(source) / filename
destpath = Path(dest) / filename
filesystem.copy(sourcepath, destpath) #(3)
elif dest_hashes[sha] != filename:
olddestpath = Path(dest) / dest_hashes[sha]
newdestpath = Path(dest) / filename
filesystem.move(olddestpath, newdestpath) #(3)
for sha, filename in dest_hashes.items():
if sha not in source_hashes:
filesystem.delete(dest / filename) #(3)-
我们的顶层函数现在公开了一个新的依赖项,即
FileSystem。 -
我们调用
filesystem.read()来生成我们的文件字典。 -
我们调用 FileSystem 的
.copy()、.move()和.delete()方法来应用我们检测到的更改。
|
提示
|
虽然我们正在使用依赖注入,但没有必要定义抽象基类或任何类型的显式接口。在本书中,我们经常展示 ABC,因为我们希望它们帮助您理解抽象是什么,但它们不是必需的。Python 的动态特性意味着我们始终可以依赖鸭子类型。 |
我们的 FileSystem 抽象的真实(默认)实现执行真实的 I/O
class FileSystem:
def read(self, path):
return read_paths_and_hashes(path)
def copy(self, source, dest):
shutil.copyfile(source, dest)
def move(self, source, dest):
shutil.move(source, dest)
def delete(self, dest):
os.remove(dest)但伪造的实现是我们选择的抽象的包装器,而不是执行真实的 I/O
class FakeFilesystem:
def __init__(self, path_hashes): #(1)
self.path_hashes = path_hashes
self.actions = [] #(2)
def read(self, path):
return self.path_hashes[path] #(1)
def copy(self, source, dest):
self.actions.append(('COPY', source, dest)) #(2)
def move(self, source, dest):
self.actions.append(('MOVE', source, dest)) #(2)
def delete(self, dest):
self.actions.append(('DELETE', dest)) #(2)-
我们使用我们选择的抽象来表示文件系统状态来初始化我们的伪造文件系统:哈希到路径的字典。
-
我们
FakeFileSystem中的操作方法只是将记录附加到.actions列表中,以便我们稍后可以检查它。这意味着我们的测试替身既是“伪造对象”又是“间谍”。
所以现在我们的测试可以作用于真实的顶层 sync() 入口点,但它们使用 FakeFilesystem() 来做到这一点。就它们的设置和断言而言,它们最终看起来与我们在直接针对功能核心 determine_actions() 函数进行测试时编写的测试非常相似
def test_when_a_file_exists_in_the_source_but_not_the_destination():
fakefs = FakeFilesystem({
'/src': {"hash1": "fn1"},
'/dst': {},
})
sync('/src', '/dst', filesystem=fakefs)
assert fakefs.actions == [("COPY", Path("/src/fn1"), Path("/dst/fn1"))]
def test_when_a_file_has_been_renamed_in_the_source():
fakefs = FakeFilesystem({
'/src': {"hash1": "fn1"},
'/dst': {"hash1": "fn2"},
})
sync('/src', '/dst', filesystem=fakefs)
assert fakefs.actions == [("MOVE", Path("/dst/fn2"), Path("/dst/fn1"))]这种方法的优点是我们的测试作用于与我们的生产代码使用的完全相同的函数。缺点是我们必须使我们的有状态组件显式化并将它们传递出去。Ruby on Rails 的创建者 David Heinemeier Hansson 曾将此著名地描述为“测试诱导的设计损坏”。
无论哪种情况,我们现在都可以着手修复我们实现中的所有错误;现在枚举所有边缘案例的测试要容易得多。
为什么不直接修补它?
此时,您可能会挠头并思考,“为什么你不直接使用 mock.patch 并节省自己的精力?”
我们在本书和我们的生产代码中都避免使用模拟。我们不打算发动圣战,但我们的直觉是,模拟框架,特别是猴子补丁,是一种代码异味。
相反,我们喜欢清楚地识别我们代码库中的职责,并将这些职责分离到小的、专注的对象中,这些对象很容易用测试替身替换。
|
注意
|
您可以在 [chapter_08_events_and_message_bus] 中看到一个示例,我们在其中 mock.patch() 掉了一个电子邮件发送模块,但最终我们在 [chapter_13_dependency_injection] 中将其替换为显式的依赖注入。 |
我们有三个密切相关的原因来支持我们的偏好
-
修补掉您正在使用的依赖项可以对代码进行单元测试,但它无助于改进设计。使用
mock.patch不会让您的代码与--dry-run标志一起工作,也不会帮助您针对 FTP 服务器运行。为此,您需要引入抽象。 -
使用模拟的测试往往与代码库的实现细节更紧密地耦合。这是因为模拟测试验证事物之间的交互:我们是否使用正确的参数调用了
shutil.copy?根据我们的经验,代码和测试之间的这种耦合往往会使测试更加脆弱。 -
过度使用模拟会导致复杂的测试套件,而这些测试套件无法解释代码。
|
注意
|
为可测试性而设计实际上意味着为可扩展性而设计。我们为了更清晰的设计而牺牲了一点复杂性,这种设计允许新的用例。 |
我们将 TDD 视为首先是一种设计实践,其次是一种测试实践。测试充当我们设计选择的记录,并在我们长期缺席后返回代码时帮助我们解释系统。
使用过多模拟的测试会被设置代码淹没,而这些设置代码隐藏了我们关心的故事。
Steve Freeman 在他的演讲 "Test-Driven Development" 中有一个过度模拟测试的精彩示例。您还应该查看我们的尊敬的技术审阅员 Ed Jung 的 PyCon 演讲 "Mocking and Patching Pitfalls",该演讲也讨论了模拟及其替代方案。
在我们推荐演讲的同时,请查看 Brandon Rhodes 在 "Hoisting Your I/O" 中的精彩演讲。它实际上不是关于模拟,而是关于将业务逻辑与 I/O 解耦的总体问题,在其中他使用了一个非常简单的说明性示例。
|
提示
|
在本章中,我们花费了大量时间用单元测试替换端到端测试。这并不意味着我们认为您永远不应该使用 E2E 测试!在本书中,我们将展示一些技术,使您能够获得一个体面的测试金字塔,其中包含尽可能多的单元测试,以及让您感到自信所需的最小数量的 E2E 测试。继续阅读 [types_of_test_rules_of_thumb] 以了解更多详细信息。 |
总结
我们将在本书中一遍又一遍地看到这个想法:我们可以通过简化业务逻辑和混乱的 I/O 之间的接口,使我们的系统更易于测试和维护。找到正确的抽象是棘手的,但这里有一些启发式方法和要问自己的问题
-
我可以选择一个熟悉的 Python 数据结构来表示混乱系统的状态,然后尝试想象一个可以返回该状态的单一函数吗?
-
将什么与如何分开:我可以使用数据结构或 DSL 来表示我希望发生的外部效果,而与我计划如何实现它们无关吗?
-
我可以在哪里在我的系统之间划一条线,我可以在哪里雕刻出一个 接缝 来插入该抽象?
-
将事物划分为具有不同职责的组件的明智方法是什么?我可以使哪些隐式概念显式化?
-
依赖项是什么,核心业务逻辑是什么?
熟能生巧!现在回到我们的常规编程……