
11: 事件驱动架构:使用事件集成微服务
在前一章中,我们实际上从未讨论过如何接收“批量数量已更改”事件,或者实际上,我们如何向外界通知重新分配。
我们有一个带有 Web API 的微服务,但是与其他系统通信的其他方式呢?我们如何知道,比如说,发货延迟或数量被修改了?我们如何告诉仓库系统订单已分配并且需要发送给客户?
在本章中,我们想展示如何扩展事件隐喻,以涵盖我们处理来自系统的传入和传出消息的方式。在内部,我们应用程序的核心现在是一个消息处理器。让我们继续下去,使其也成为外部的消息处理器。如图 我们的应用程序是一个消息处理器 所示,我们的应用程序将通过外部消息总线(我们将使用 Redis pub/sub 队列作为示例)接收来自外部源的事件,并将其输出以事件的形式发布回那里。
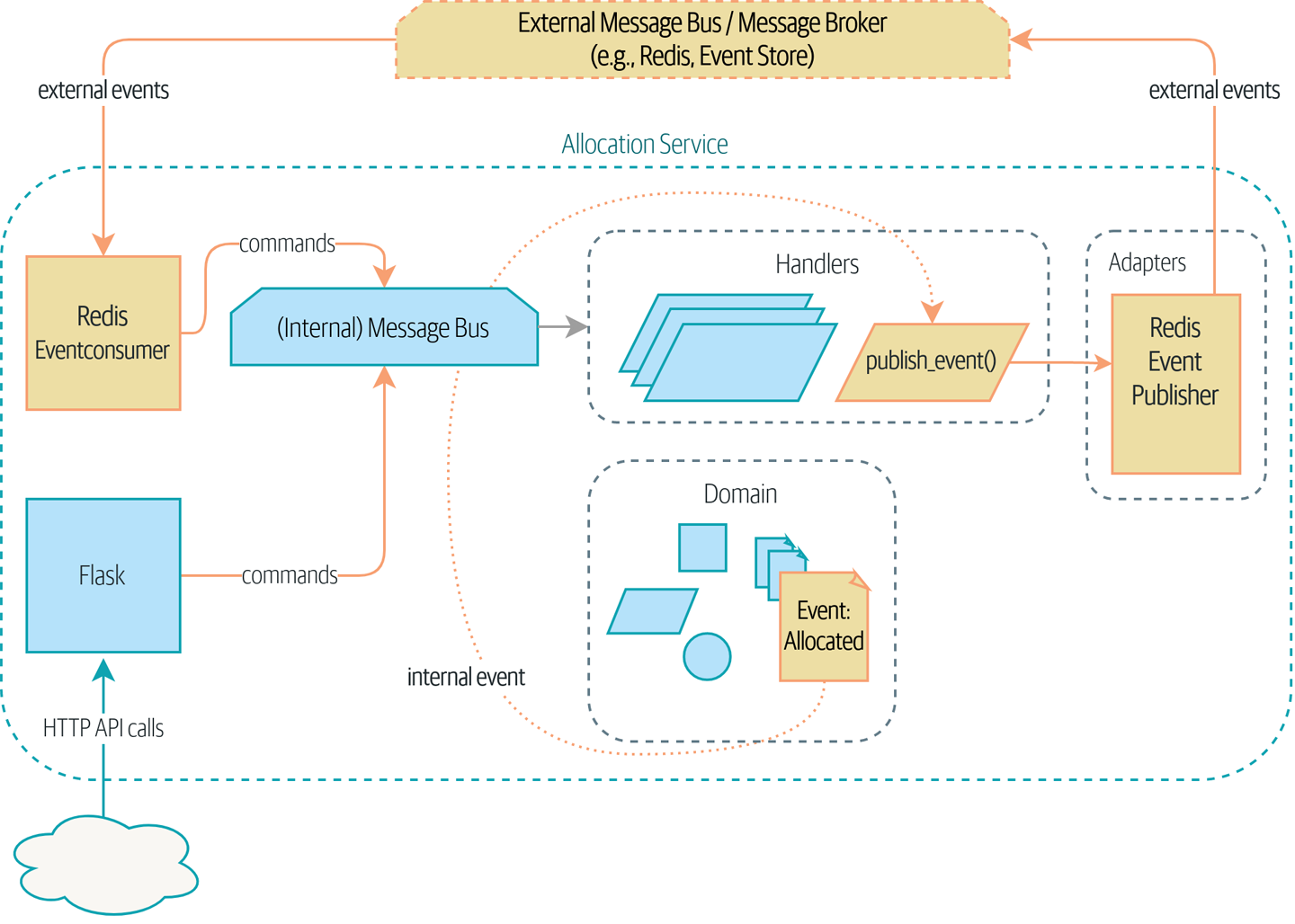
|
提示
|
本章的代码位于 chapter_11_external_events 分支 GitHub 上 git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_11_external_events # or to code along, checkout the previous chapter: git checkout chapter_10_commands |
分布式泥球,以及名词式思维
在我们深入探讨之前,让我们谈谈替代方案。我们经常与试图构建微服务架构的工程师交谈。他们通常是从现有应用程序迁移而来,他们的第一反应是将系统拆分为名词。
到目前为止,我们在系统中引入了哪些名词?嗯,我们有批量库存、订单、产品和客户。因此,一种将系统分解的幼稚尝试可能看起来像 基于名词的服务上下文图(请注意,我们以名词 Batches 而不是 Allocation 命名了我们的系统)。

[plantuml, apwp_1102, config=plantuml.cfg] @startuml Batches Context Diagram !include images/C4_Context.puml System(batches, "Batches", "Knows about available stock") Person(customer, "Customer", "Wants to buy furniture") System(orders, "Orders", "Knows about customer orders") System(warehouse, "Warehouse", "Knows about shipping instructions") Rel_R(customer, orders, "Places order with") Rel_D(orders, batches, "Reserves stock with") Rel_D(batches, warehouse, "Sends instructions to") @enduml
我们系统中的每个“事物”都有一个关联的服务,该服务公开了一个 HTTP API。
让我们通过 命令流 1 中的示例 happy-path 流程:我们的用户访问网站,可以从有库存的产品中进行选择。当他们将商品添加到购物车时,我们将为他们预留一些库存。当订单完成时,我们确认预留,这将导致我们向仓库发送调度指令。我们再假设,如果这是客户的第三个订单,我们希望更新客户记录以将其标记为 VIP。
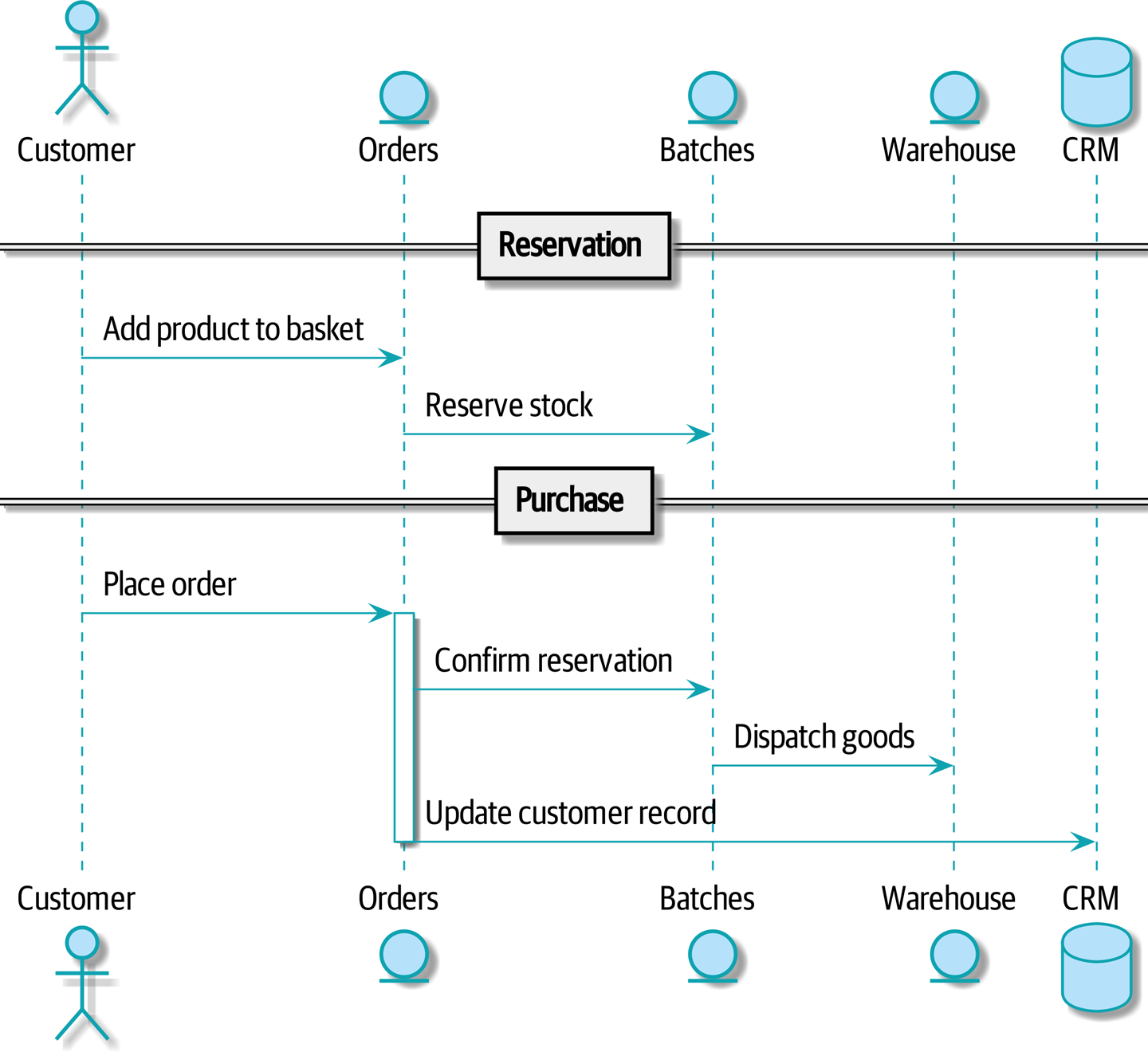
[plantuml, apwp_1103, config=plantuml.cfg] @startuml scale 4 actor Customer entity Orders entity Batches entity Warehouse database CRM == Reservation == Customer -> Orders: Add product to basket Orders -> Batches: Reserve stock == Purchase == Customer -> Orders: Place order activate Orders Orders -> Batches: Confirm reservation Batches -> Warehouse: Dispatch goods Orders -> CRM: Update customer record deactivate Orders @enduml
我们可以将这些步骤中的每一步都视为系统中的一个命令:ReserveStock、ConfirmReservation、DispatchGoods、MakeCustomerVIP 等等。
这种架构风格,我们为每个数据库表创建一个微服务,并将我们的 HTTP API 视为贫血模型的 CRUD 接口,是人们最常用来处理面向服务的设计的初始方式。
对于非常简单的系统,这可以正常工作,但是它可能会迅速退化为分布式泥球。
为了了解原因,让我们考虑另一种情况。有时,当库存到达仓库时,我们发现物品在运输过程中被水损坏。我们不能出售水损坏的沙发,因此我们必须将其丢弃并从我们的合作伙伴那里请求更多库存。我们还需要更新我们的库存模型,这可能意味着我们需要重新分配客户的订单。
这个逻辑放在哪里?
嗯,仓库系统知道库存已损坏,因此也许它应该拥有这个过程,如图 命令流 2 所示。
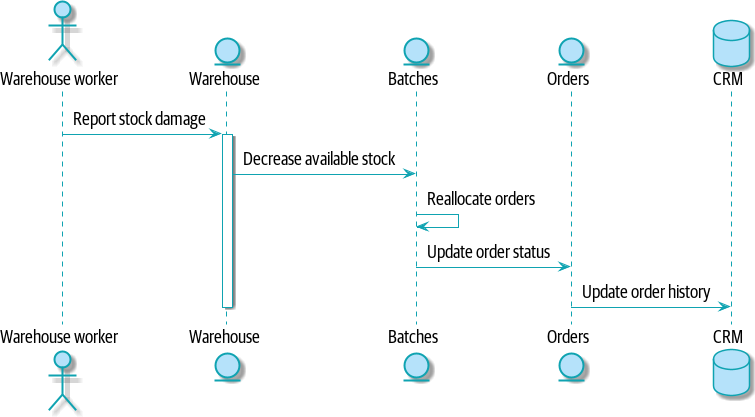
[plantuml, apwp_1104, config=plantuml.cfg] @startuml scale 4 actor w as "Warehouse worker" entity Warehouse entity Batches entity Orders database CRM w -> Warehouse: Report stock damage activate Warehouse Warehouse -> Batches: Decrease available stock Batches -> Batches: Reallocate orders Batches -> Orders: Update order status Orders -> CRM: Update order history deactivate Warehouse @enduml
这种方式也行得通,但是现在我们的依赖图很混乱。为了分配库存,订单服务驱动批次系统,批次系统驱动仓库;但是为了处理仓库中的问题,我们的仓库系统驱动批次,批次驱动订单。
将此乘以我们需要提供的所有其他工作流程,您可以看到服务如何快速纠缠在一起。
分布式系统中的错误处理
“事物会崩溃”是软件工程的普遍规律。当我们的一个请求失败时,我们的系统中会发生什么?假设在我们接受用户订购三个 MISBEGOTTEN-RUG 的订单后立即发生网络错误,如图 带有错误的命令流 所示。
我们在这里有两种选择:我们可以无论如何都下订单并使其未分配,或者我们可以拒绝接受订单,因为无法保证分配。我们的批次服务的失败状态已经冒泡,并正在影响我们的订单服务的可靠性。
当两件事必须一起更改时,我们说它们是耦合的。我们可以将这种故障级联视为一种时间耦合:系统的每个部分都必须同时工作,系统的任何部分才能工作。随着系统变得越来越大,某些部分降级的可能性呈指数级增长。
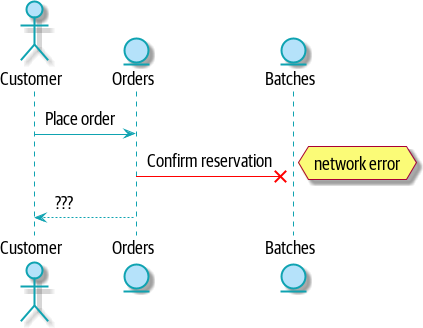
[plantuml, apwp_1105, config=plantuml.cfg] @startuml scale 4 actor Customer entity Orders entity Batches Customer -> Orders: Place order Orders -[#red]x Batches: Confirm reservation hnote right: network error Orders --> Customer: ??? @enduml
替代方案:使用异步消息传递的时间解耦
我们如何获得适当的耦合?我们已经看到了答案的一部分,那就是我们应该以动词而不是名词来思考。我们的领域模型是关于建模业务流程。它不是关于事物的静态数据模型;它是动词的模型。
因此,与其考虑订单系统和批次系统,不如考虑订购系统和分配系统,等等。
当我们以这种方式分离事物时,更容易看出哪个系统应该负责什么。在考虑订购时,我们真正想确保的是,当我们下订单时,订单已下达。其他一切都可以稍后发生,只要它发生即可。
|
注意
|
如果这听起来很熟悉,那应该是的!隔离职责与我们设计聚合和命令时经历的过程相同。 |
与聚合一样,微服务应该是一致性边界。在两个服务之间,我们可以接受最终一致性,这意味着我们不需要依赖同步调用。每个服务都接受来自外部世界的命令,并引发事件以记录结果。其他服务可以监听这些事件以触发工作流程中的后续步骤。
为了避免分布式泥球反模式,我们希望使用异步消息传递来集成我们的系统,而不是时间耦合的 HTTP API 调用。我们希望我们的 BatchQuantityChanged 消息作为来自上游系统的外部消息传入,并且我们希望我们的系统发布 Allocated 事件,供下游系统监听。
为什么这样更好?首先,因为事物可以独立失败,所以更容易处理降级行为:如果分配系统状况不佳,我们仍然可以接受订单。
其次,我们正在降低系统之间耦合的强度。如果我们需要更改操作顺序或在流程中引入新步骤,我们可以在本地执行此操作。
使用 Redis Pub/Sub 通道进行集成
让我们看看它将如何具体工作。我们需要某种方式将事件从一个系统传出并传入另一个系统,就像我们的消息总线一样,但用于服务。这种基础设施通常称为消息代理。消息代理的角色是从发布者那里接收消息并将它们传递给订阅者。
在 MADE.com,我们使用 Event Store;Kafka 或 RabbitMQ 是有效的替代方案。基于 Redis pub/sub 通道 的轻量级解决方案也可以正常工作,并且由于 Redis 对人们来说更普遍熟悉,因此我们认为我们会在本书中使用它。
|
注意
|
我们正在掩盖选择正确消息传递平台所涉及的复杂性。诸如消息排序、故障处理和幂等性等问题都需要仔细考虑。有关一些提示,请参阅 [陷阱]。 |
我们的新流程将类似于 重新分配流程的序列图:Redis 提供启动整个流程的 BatchQuantityChanged 事件,并且我们的 Allocated 事件在最后再次发布回 Redis。
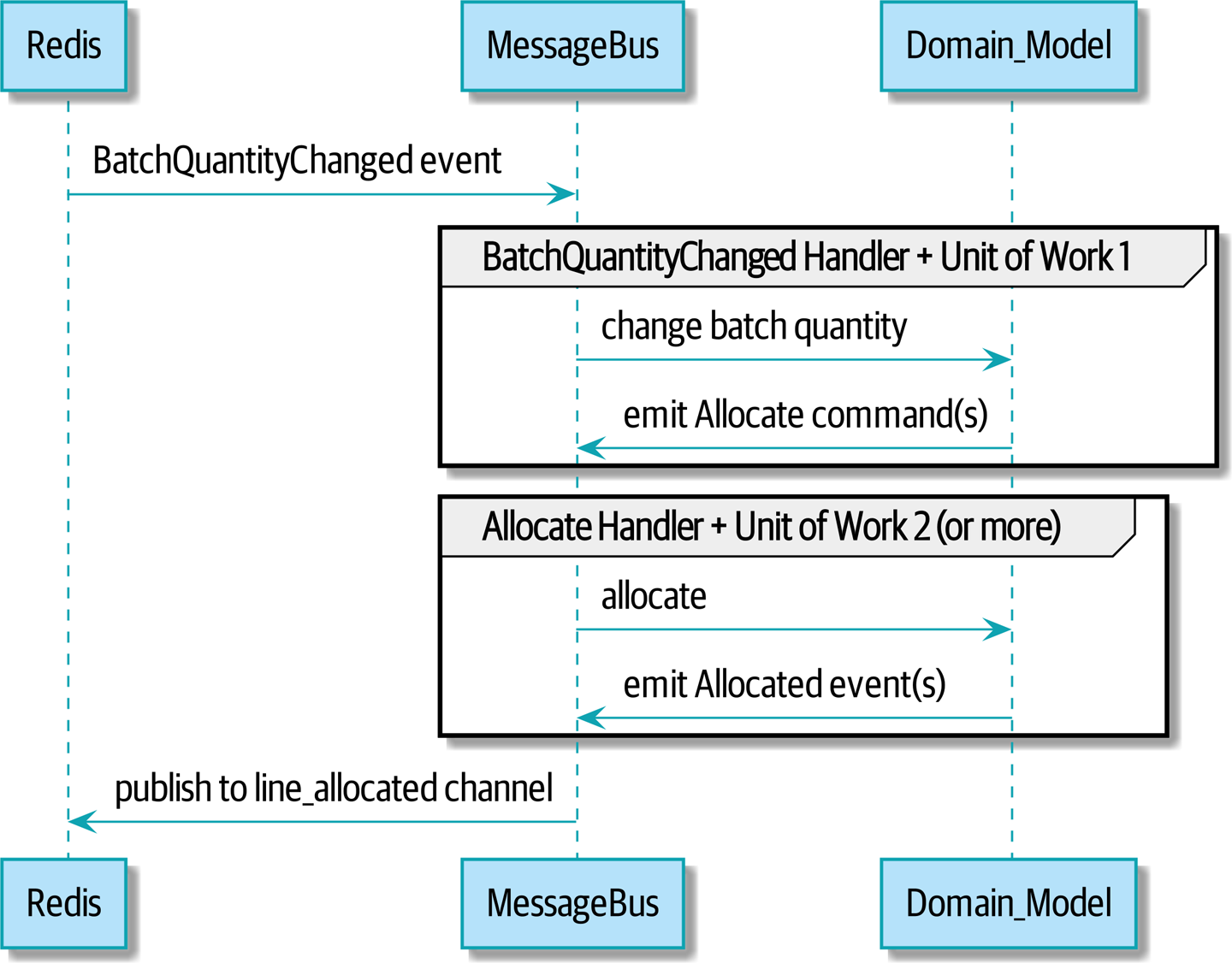
[plantuml, apwp_1106, config=plantuml.cfg]
@startuml
scale 4
Redis -> MessageBus : BatchQuantityChanged event
group BatchQuantityChanged Handler + Unit of Work 1
MessageBus -> Domain_Model : change batch quantity
Domain_Model -> MessageBus : emit Allocate command(s)
end
group Allocate Handler + Unit of Work 2 (or more)
MessageBus -> Domain_Model : allocate
Domain_Model -> MessageBus : emit Allocated event(s)
end
MessageBus -> Redis : publish to line_allocated channel
@enduml
使用端到端测试驱动一切
以下是我们如何开始进行端到端测试。我们可以使用现有的 API 创建批次,然后我们将测试传入和传出消息
def test_change_batch_quantity_leading_to_reallocation():
# start with two batches and an order allocated to one of them #(1)
orderid, sku = random_orderid(), random_sku()
earlier_batch, later_batch = random_batchref("old"), random_batchref("newer")
api_client.post_to_add_batch(earlier_batch, sku, qty=10, eta="2011-01-01") #(2)
api_client.post_to_add_batch(later_batch, sku, qty=10, eta="2011-01-02")
response = api_client.post_to_allocate(orderid, sku, 10) #(2)
assert response.json()["batchref"] == earlier_batch
subscription = redis_client.subscribe_to("line_allocated") #(3)
# change quantity on allocated batch so it's less than our order #(1)
redis_client.publish_message( #(3)
"change_batch_quantity",
{"batchref": earlier_batch, "qty": 5},
)
# wait until we see a message saying the order has been reallocated #(1)
messages = []
for attempt in Retrying(stop=stop_after_delay(3), reraise=True): #(4)
with attempt:
message = subscription.get_message(timeout=1)
if message:
messages.append(message)
print(messages)
data = json.loads(messages[-1]["data"])
assert data["orderid"] == orderid
assert data["batchref"] == later_batch-
您可以从注释中阅读此测试中发生的事情的故事:我们想向系统中发送一个事件,该事件导致重新分配订单行,并且我们看到该重新分配也作为 Redis 中的事件出现。
-
api_client是一个小助手,我们重构出来在我们的两种测试类型之间共享;它包装了我们对requests.post的调用。 -
redis_client是另一个小的测试助手,其细节实际上并不重要;它的工作是能够从各种 Redis 通道发送和接收消息。我们将使用一个名为change_batch_quantity的通道来发送我们更改批次数量的请求,并且我们将监听另一个名为line_allocated的通道,以查找预期的重新分配。 -
由于被测系统的异步性质,我们需要再次使用
tenacity库来添加重试循环——首先,因为我们的新line_allocated消息可能需要一段时间才能到达,而且因为它不会是该通道上的唯一消息。
Redis 是围绕我们消息总线的另一个轻薄适配器
我们的 Redis pub/sub 监听器(我们称之为事件消费者)非常像 Flask:它从外部世界转换为我们的事件
r = redis.Redis(**config.get_redis_host_and_port())
def main():
orm.start_mappers()
pubsub = r.pubsub(ignore_subscribe_messages=True)
pubsub.subscribe("change_batch_quantity") #(1)
for m in pubsub.listen():
handle_change_batch_quantity(m)
def handle_change_batch_quantity(m):
logging.debug("handling %s", m)
data = json.loads(m["data"]) #(2)
cmd = commands.ChangeBatchQuantity(ref=data["batchref"], qty=data["qty"]) #(2)
messagebus.handle(cmd, uow=unit_of_work.SqlAlchemyUnitOfWork())-
main()在加载时将我们订阅到change_batch_quantity通道。 -
作为系统入口点,我们的主要工作是反序列化 JSON,将其转换为
Command,并将其传递给服务层——就像 Flask 适配器所做的那样。
我们还构建了一个新的下游适配器来执行相反的工作——将领域事件转换为公共事件
r = redis.Redis(**config.get_redis_host_and_port())
def publish(channel, event: events.Event): #(1)
logging.debug("publishing: channel=%s, event=%s", channel, event)
r.publish(channel, json.dumps(asdict(event)))-
我们在这里采用硬编码通道,但是您也可以存储事件类/名称和适当通道之间的映射,从而允许一个或多个消息类型转到不同的通道。
我们新的传出事件
以下是 Allocated 事件的外观
@dataclass
class Allocated(Event):
orderid: str
sku: str
qty: int
batchref: str它捕获了我们需要了解的关于分配的所有信息:订单行的详细信息,以及它分配给哪个批次。
我们将其添加到模型的 allocate() 方法中(首先添加了一个测试,这是自然的)
class Product:
...
def allocate(self, line: OrderLine) -> str:
...
batch.allocate(line)
self.version_number += 1
self.events.append(
events.Allocated(
orderid=line.orderid,
sku=line.sku,
qty=line.qty,
batchref=batch.reference,
)
)
return batch.referenceChangeBatchQuantity 的处理程序已经存在,因此我们需要添加的只是发布传出事件的处理程序
HANDLERS = {
events.Allocated: [handlers.publish_allocated_event],
events.OutOfStock: [handlers.send_out_of_stock_notification],
} # type: Dict[Type[events.Event], List[Callable]]发布事件使用来自 Redis 包装器的助手函数
def publish_allocated_event(
event: events.Allocated,
uow: unit_of_work.AbstractUnitOfWork,
):
redis_eventpublisher.publish("line_allocated", event)内部事件与外部事件
保持内部事件和外部事件之间的区别清晰是一个好主意。有些事件可能来自外部,有些事件可能会升级并在外部发布,但并非所有事件都会如此。如果您深入研究 事件溯源(非常适合另一本书的主题),这一点尤其重要。
|
提示
|
传出事件是应用验证的重要场所之一。有关一些验证哲学和 示例,请参阅 [appendix_validation]。 |
总结
事件可以来自外部,但它们也可以在外部发布——我们的 publish 处理程序将事件转换为 Redis 通道上的消息。我们使用事件与外界对话。这种时间解耦为我们的应用程序集成带来了很大的灵活性,但与往常一样,这是有代价的。
事件通知很好,因为它意味着低耦合级别,并且设置起来非常简单。但是,如果确实存在跨越各种事件通知的逻辑流程,则可能会变得有问题……很难看到这样的流程,因为它在任何程序文本中都不是显式的……这可能会使调试和修改变得困难。
Martin Fowler,"你所说的“事件驱动”是什么意思"
基于事件的微服务集成:权衡 展示了一些需要考虑的权衡。
| 优点 | 缺点 |
|---|---|
|
|
更一般而言,如果您从同步消息传递模型转向异步模型,那么您还会遇到与消息可靠性和最终一致性相关的一系列问题。请继续阅读 [陷阱]。