
13:依赖注入(以及引导启动)
在 Python 世界中,依赖注入 (DI) 受到怀疑。而且到目前为止,在我们本书的示例代码中,我们已经很好地在没有它的情况下管理了!
在本章中,我们将探讨代码中的一些痛点,这些痛点促使我们考虑使用 DI,并且我们将介绍一些实现 DI 的选项,让您选择您认为最 Pythonic 的方式。
我们还将向我们的架构添加一个新组件,称为bootstrap.py;它将负责依赖注入,以及我们经常需要的其他一些初始化工作。我们将解释为什么这种东西在 OO 语言中被称为组合根,以及为什么引导脚本对于我们的目的来说就足够了。
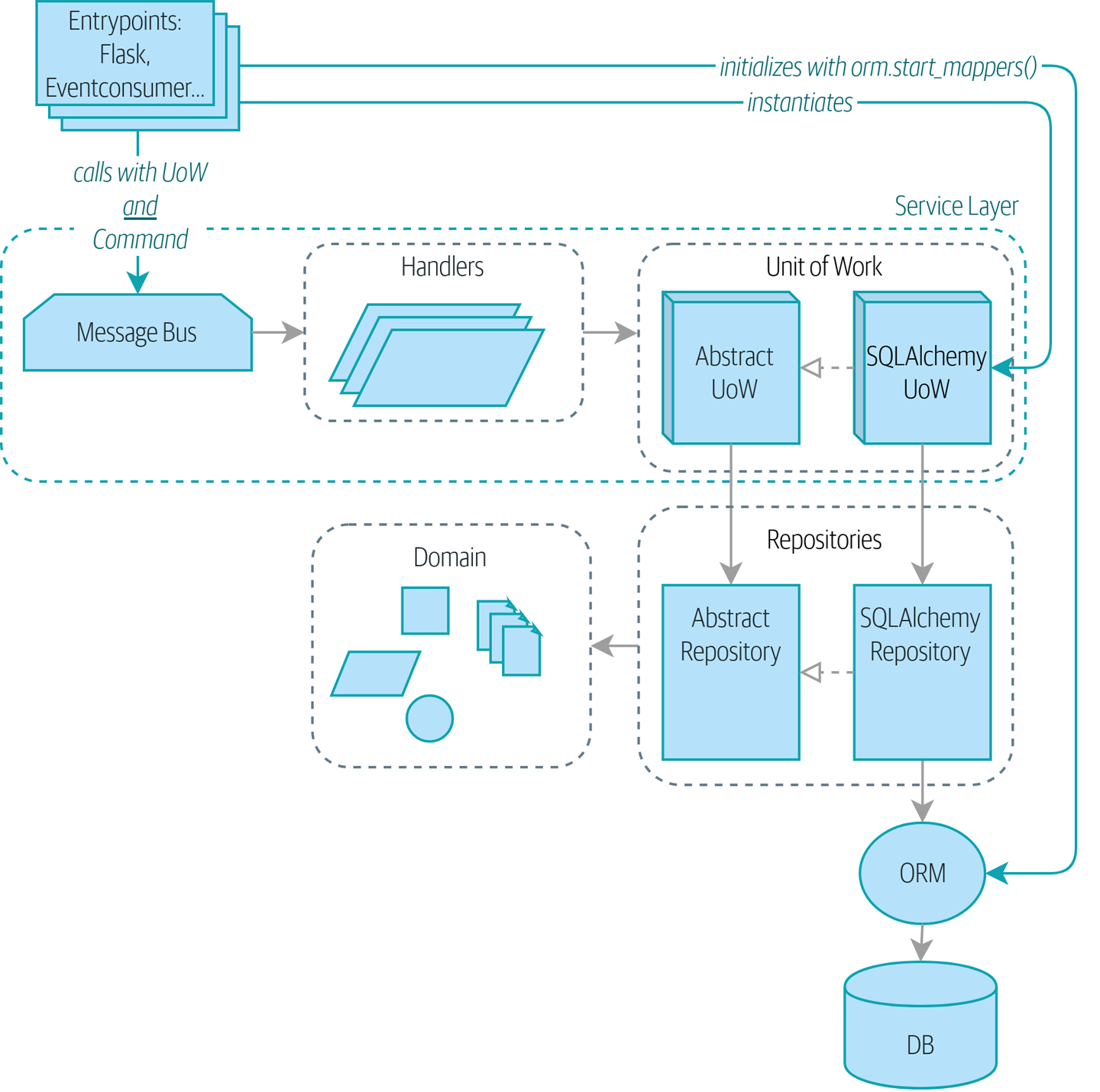
没有引导启动:入口点做了很多事情 展示了没有引导启动器时我们的应用程序是什么样的:入口点做了很多初始化工作,并将我们的主要依赖项 UoW 传递出去。
|
提示
|
如果您还没有阅读过 [chapter_03_abstractions],那么在继续本章之前,值得阅读一下,特别是关于函数式与面向对象依赖管理的讨论。 |
|
提示
|
本章的代码位于 chapter_13_dependency_injection 分支 GitHub 上 git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_13_dependency_injection # or to code along, checkout the previous chapter: git checkout chapter_12_cqrs |
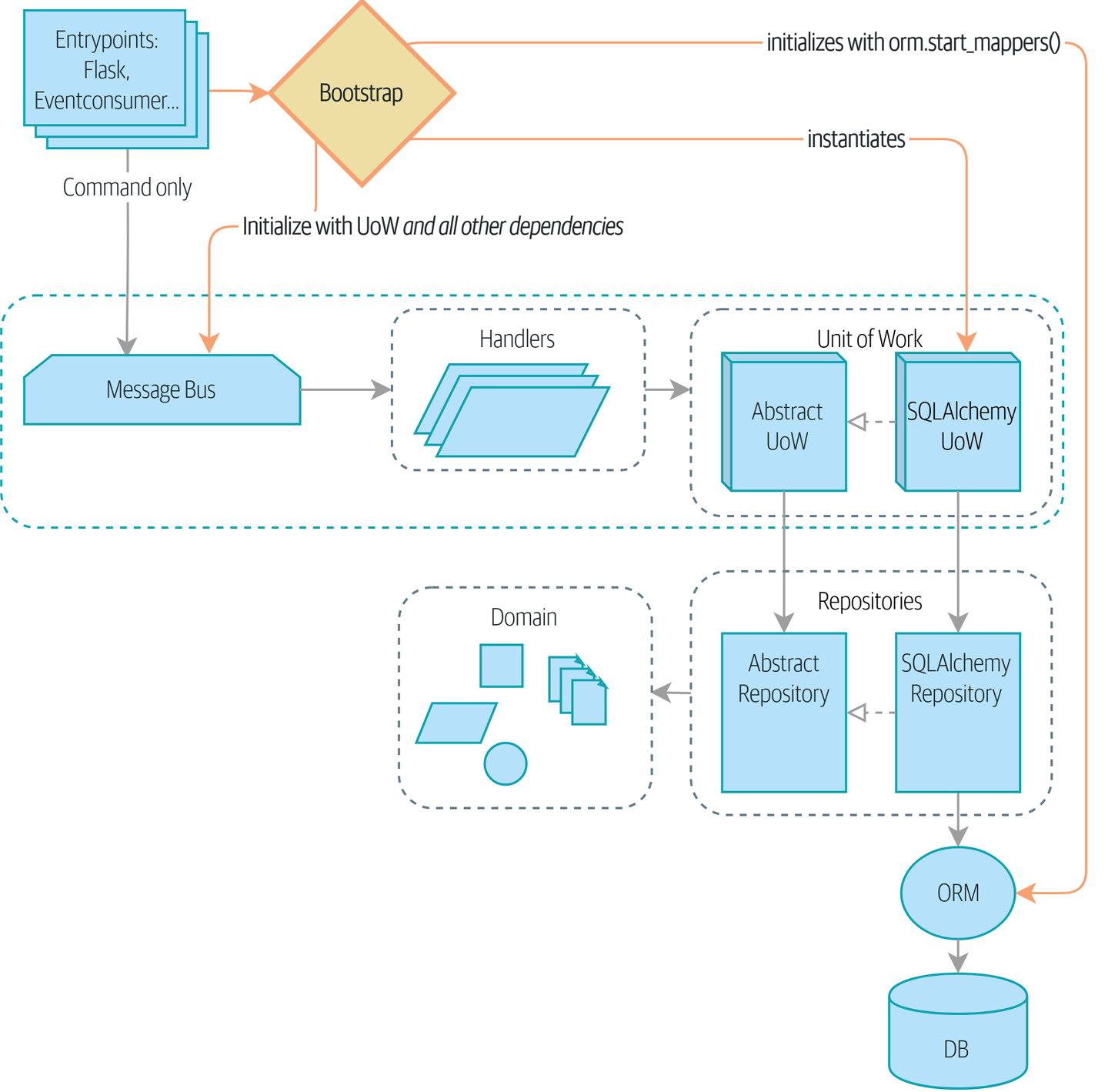
引导启动在一个地方处理所有这些事情 展示了我们的引导启动器接管了这些职责。
隐式依赖与显式依赖
根据您特定的脑类型,您可能在此时会感到一丝不安。让我们把它公开化。我们已经向您展示了管理依赖项和测试它们的两种方法。
对于我们的数据库依赖项,我们构建了一个仔细的显式依赖项框架,以及在测试中覆盖它们的简单选项。我们的主要处理函数声明了对 UoW 的显式依赖
def allocate(
cmd: commands.Allocate,
uow: unit_of_work.AbstractUnitOfWork,
):这使得在我们的服务层测试中轻松换入一个假的 UoW
uow = FakeUnitOfWork()
messagebus.handle([...], uow)UoW 本身声明了对会话工厂的显式依赖
class SqlAlchemyUnitOfWork(AbstractUnitOfWork):
def __init__(self, session_factory=DEFAULT_SESSION_FACTORY):
self.session_factory = session_factory
...我们在集成测试中利用它,以便有时可以使用 SQLite 而不是 Postgres
def test_rolls_back_uncommitted_work_by_default(sqlite_session_factory):
uow = unit_of_work.SqlAlchemyUnitOfWork(sqlite_session_factory) #(1)-
集成测试将默认的 Postgres
session_factory替换为 SQLite 的。
显式依赖项难道不完全是奇怪且 Java-y 的吗?
如果您习惯了 Python 中通常发生的事情,您会认为这一切有点奇怪。标准的做法是通过简单地导入来隐式声明我们的依赖项,然后如果我们需要在测试中更改它,我们可以进行猴子补丁,这在动态语言中是正确且真实的
from allocation.adapters import email, redis_eventpublisher #(1)
...
def send_out_of_stock_notification(
event: events.OutOfStock,
uow: unit_of_work.AbstractUnitOfWork,
):
email.send( #(2)
"stock@made.com",
f"Out of stock for {event.sku}",
)-
硬编码导入
-
直接调用特定的电子邮件发送器
为什么为了我们的测试而用不必要的参数污染我们的应用程序代码?mock.patch 使猴子补丁变得简单易用
with mock.patch("allocation.adapters.email.send") as mock_send_mail:
...问题在于,我们把它弄得看起来很容易,因为我们的玩具示例不发送真实的电子邮件(email.send_mail 只是做了 print),但在现实生活中,您最终将不得不为每个可能导致缺货通知的测试调用 mock.patch。如果您在代码库中使用过大量用于防止不必要的副作用的 mocks,您就会知道 mocky 样板代码有多么烦人。
您也会知道 mocks 将我们紧密地耦合到实现。通过选择猴子补丁 email.send_mail,我们将绑定到执行 import email,如果我们想执行 from email import send_mail,这是一个简单的重构,我们将不得不更改我们所有的 mocks。
所以这是一个权衡。是的,严格来说,声明显式依赖项是不必要的,并且使用它们会使我们的应用程序代码稍微复杂一些。但作为回报,我们将获得更易于编写和管理的测试。
最重要的是,声明显式依赖项是依赖倒置原则的一个例子——与其对特定细节具有(隐式)依赖项,不如对抽象具有(显式)依赖项
显式优于隐式。
def send_out_of_stock_notification(
event: events.OutOfStock,
send_mail: Callable,
):
send_mail(
"stock@made.com",
f"Out of stock for {event.sku}",
)但是,如果我们真的更改为显式声明所有这些依赖项,谁将注入它们,以及如何注入?到目前为止,我们实际上只处理了传递 UoW:我们的测试使用 FakeUnitOfWork,而 Flask 和 Redis eventconsumer 入口点使用真实的 UoW,消息总线将它们传递给我们的命令处理程序。如果我们添加真实和假的电子邮件类,谁将创建它们并将它们传递下去?
它需要在进程生命周期中尽可能早地发生,因此最明显的位置是在我们的入口点中。这将意味着 Flask 和 Redis 中以及我们的测试中都有额外的(重复的)垃圾代码。我们还必须将传递依赖项的责任添加到消息总线,消息总线已经有工作要做了;这感觉像是违反了 SRP。
相反,我们将使用一种称为组合根(对您和我来说是引导脚本)的模式,[1] 并且我们将进行一些“手动 DI”(没有框架的依赖注入)。请参阅 入口点和消息总线之间的引导启动器。[2]

[ditaa, apwp_1303]
+---------------+
| Entrypoints |
| (Flask/Redis) |
+---------------+
|
| call
V
/--------------\
| | prepares handlers with correct dependencies injected in
| Bootstrapper | (test bootstrapper will use fakes, prod one will use real)
| |
\--------------/
|
| pass injected handlers to
V
/---------------\
| Message Bus |
+---------------+
|
| dispatches events and commands to injected handlers
|
V
准备处理程序:使用闭包和 partial 手动 DI
将具有依赖项的函数转换为准备好稍后使用已注入的这些依赖项调用的函数的一种方法是使用闭包或 partial 函数将函数与其依赖项组合起来
# existing allocate function, with abstract uow dependency
def allocate(
cmd: commands.Allocate,
uow: unit_of_work.AbstractUnitOfWork,
):
line = OrderLine(cmd.orderid, cmd.sku, cmd.qty)
with uow:
...
# bootstrap script prepares actual UoW
def bootstrap(..):
uow = unit_of_work.SqlAlchemyUnitOfWork()
# prepare a version of the allocate fn with UoW dependency captured in a closure
allocate_composed = lambda cmd: allocate(cmd, uow)
# or, equivalently (this gets you a nicer stack trace)
def allocate_composed(cmd):
return allocate(cmd, uow)
# alternatively with a partial
import functools
allocate_composed = functools.partial(allocate, uow=uow) #(1)
# later at runtime, we can call the partial function, and it will have
# the UoW already bound
allocate_composed(cmd)-
闭包(lambdas 或命名函数)和
functools.partial之间的区别在于前者使用 变量的延迟绑定,如果任何依赖项是可变的,这可能会成为困惑的根源。
这是 send_out_of_stock_notification() 处理程序的相同模式,它具有不同的依赖项
def send_out_of_stock_notification(
event: events.OutOfStock,
send_mail: Callable,
):
send_mail(
"stock@made.com",
...
# prepare a version of the send_out_of_stock_notification with dependencies
sosn_composed = lambda event: send_out_of_stock_notification(event, email.send_mail)
...
# later, at runtime:
sosn_composed(event) # will have email.send_mail already injected in使用类的替代方案
闭包和 partial 函数对于做过一些函数式编程的人来说会感到熟悉。这是一个使用类的替代方案,它可能对其他人有吸引力。但这需要将我们所有的处理函数重写为类
# we replace the old `def allocate(cmd, uow)` with:
class AllocateHandler:
def __init__(self, uow: unit_of_work.AbstractUnitOfWork): #(2)
self.uow = uow
def __call__(self, cmd: commands.Allocate): #(1)
line = OrderLine(cmd.orderid, cmd.sku, cmd.qty)
with self.uow:
# rest of handler method as before
...
# bootstrap script prepares actual UoW
uow = unit_of_work.SqlAlchemyUnitOfWork()
# then prepares a version of the allocate fn with dependencies already injected
allocate = AllocateHandler(uow)
...
# later at runtime, we can call the handler instance, and it will have
# the UoW already injected
allocate(cmd)-
该类旨在生成一个可调用的函数,因此它具有 __call__ 方法。
-
但是我们使用
init来声明它需要的依赖项。如果您曾经制作过基于类的描述符,或者一个接受参数的基于类的上下文管理器,那么这种东西会感觉很熟悉。
选择您和您的团队感觉更舒适的任何一种。
引导脚本
我们希望我们的引导脚本执行以下操作
-
声明默认依赖项,但允许我们覆盖它们
-
执行我们需要启动应用程序的“init”操作
-
将所有依赖项注入到我们的处理程序中
-
将我们应用程序的核心对象消息总线返回给我们
这是第一个版本
def bootstrap(
start_orm: bool = True, #(1)
uow: unit_of_work.AbstractUnitOfWork = unit_of_work.SqlAlchemyUnitOfWork(), #(2)
send_mail: Callable = email.send,
publish: Callable = redis_eventpublisher.publish,
) -> messagebus.MessageBus:
if start_orm:
orm.start_mappers() #(1)
dependencies = {"uow": uow, "send_mail": send_mail, "publish": publish}
injected_event_handlers = { #(3)
event_type: [
inject_dependencies(handler, dependencies)
for handler in event_handlers
]
for event_type, event_handlers in handlers.EVENT_HANDLERS.items()
}
injected_command_handlers = { #(3)
command_type: inject_dependencies(handler, dependencies)
for command_type, handler in handlers.COMMAND_HANDLERS.items()
}
return messagebus.MessageBus( #(4)
uow=uow,
event_handlers=injected_event_handlers,
command_handlers=injected_command_handlers,
)-
orm.start_mappers()是我们在应用程序开始时需要执行一次的初始化工作的示例。另一个常见的例子是设置logging模块。 -
我们可以使用参数默认值来定义正常的/生产默认值。将它们放在一个地方很好,但有时依赖项在构造时会产生一些副作用,在这种情况下,您可能更喜欢将它们默认为
None。 -
我们通过使用一个名为
inject_dependencies()的函数来构建处理程序映射的注入版本,我们将在接下来展示该函数。 -
我们返回一个配置好的消息总线,随时可以使用。
以下是我们如何通过检查函数签名将依赖项注入到处理函数中
def inject_dependencies(handler, dependencies):
params = inspect.signature(handler).parameters #(1)
deps = {
name: dependency
for name, dependency in dependencies.items() #(2)
if name in params
}
return lambda message: handler(message, **deps) #(3)-
我们检查我们的命令/事件处理程序的参数。
-
我们按名称将它们与我们的依赖项匹配。
-
我们将它们作为 kwargs 注入以生成 partial。
消息总线在运行时被赋予处理程序
我们的消息总线将不再是静态的;它需要被赋予已注入的处理程序。因此,我们将它从一个模块变成一个可配置的类
class MessageBus: #(1)
def __init__(
self,
uow: unit_of_work.AbstractUnitOfWork,
event_handlers: Dict[Type[events.Event], List[Callable]], #(2)
command_handlers: Dict[Type[commands.Command], Callable], #(2)
):
self.uow = uow
self.event_handlers = event_handlers
self.command_handlers = command_handlers
def handle(self, message: Message): #(3)
self.queue = [message] #(4)
while self.queue:
message = self.queue.pop(0)
if isinstance(message, events.Event):
self.handle_event(message)
elif isinstance(message, commands.Command):
self.handle_command(message)
else:
raise Exception(f"{message} was not an Event or Command")-
消息总线变成一个类…
-
…它被赋予了已经依赖注入的处理程序。
-
主要的
handle()函数基本相同,只有一些属性和方法移动到了self上。 -
像这样使用
self.queue不是线程安全的,如果您正在使用线程,这可能会成为问题,因为正如我们编写的那样,总线实例在 Flask 应用程序上下文中是全局的。这只是需要注意的事情。
总线中还有什么变化?
def handle_event(self, event: events.Event):
for handler in self.event_handlers[type(event)]: #(1)
try:
logger.debug("handling event %s with handler %s", event, handler)
handler(event) #(2)
self.queue.extend(self.uow.collect_new_events())
except Exception:
logger.exception("Exception handling event %s", event)
continue
def handle_command(self, command: commands.Command):
logger.debug("handling command %s", command)
try:
handler = self.command_handlers[type(command)] #(1)
handler(command) #(2)
self.queue.extend(self.uow.collect_new_events())
except Exception:
logger.exception("Exception handling command %s", command)
raise-
handle_event和handle_command基本相同,但它们使用self上的版本,而不是索引到静态的EVENT_HANDLERS或COMMAND_HANDLERS字典中。 -
我们不期望将 UoW 传递到处理程序中,而是期望处理程序已经拥有它们的所有依赖项,因此它们只需要一个参数,即特定的事件或命令。
在我们的入口点中使用引导启动
在我们应用程序的入口点中,我们现在只需调用 bootstrap.bootstrap() 并获得一个准备就绪的消息总线,而不是配置 UoW 和其余部分
-from allocation import views
+from allocation import bootstrap, views
app = Flask(__name__)
-orm.start_mappers() #(1)
+bus = bootstrap.bootstrap()
@app.route("/add_batch", methods=["POST"])
@@ -19,8 +16,7 @@ def add_batch():
cmd = commands.CreateBatch(
request.json["ref"], request.json["sku"], request.json["qty"], eta
)
- uow = unit_of_work.SqlAlchemyUnitOfWork() #(2)
- messagebus.handle(cmd, uow)
+ bus.handle(cmd) #(3)
return "OK", 201-
我们不再需要调用
start_orm();引导脚本的初始化阶段将完成该操作。 -
我们不再需要显式构建特定类型的 UoW;引导脚本默认值会处理它。
-
我们的消息总线现在是一个特定的实例,而不是全局模块。[3]
在我们的测试中初始化 DI
在测试中,我们可以使用带有覆盖默认值的 bootstrap.bootstrap() 来获得自定义消息总线。这是一个集成测试中的示例
@pytest.fixture
def sqlite_bus(sqlite_session_factory):
bus = bootstrap.bootstrap(
start_orm=True, #(1)
uow=unit_of_work.SqlAlchemyUnitOfWork(sqlite_session_factory), #(2)
send_mail=lambda *args: None, #(3)
publish=lambda *args: None, #(3)
)
yield bus
clear_mappers()
def test_allocations_view(sqlite_bus):
sqlite_bus.handle(commands.CreateBatch("sku1batch", "sku1", 50, None))
sqlite_bus.handle(commands.CreateBatch("sku2batch", "sku2", 50, today))
...
assert views.allocations("order1", sqlite_bus.uow) == [
{"sku": "sku1", "batchref": "sku1batch"},
{"sku": "sku2", "batchref": "sku2batch"},
]-
我们仍然想启动 ORM…
-
…因为我们将使用真实的 UoW,尽管是带有内存数据库的。
-
但我们不需要发送电子邮件或发布,因此我们将它们设为 noops。
在我们的单元测试中,相比之下,我们可以重用我们的 FakeUnitOfWork
def bootstrap_test_app():
return bootstrap.bootstrap(
start_orm=False, #(1)
uow=FakeUnitOfWork(), #(2)
send_mail=lambda *args: None, #(3)
publish=lambda *args: None, #(3)
)-
无需启动 ORM…
-
…因为假的 UoW 不使用 ORM。
-
我们也想伪造我们的电子邮件和 Redis 适配器。
因此,这消除了一些重复,并且我们将大量设置和合理的默认值移动到一个地方。
“正确”构建适配器:一个工作示例
为了真正了解它是如何工作的,让我们完成一个示例,说明您如何“正确地”构建适配器并为其进行依赖注入。
目前,我们有两种类型的依赖项
uow: unit_of_work.AbstractUnitOfWork, #(1)
send_mail: Callable, #(2)
publish: Callable, #(2)-
UoW 具有抽象基类。这是声明和管理外部依赖项的重量级选项。当依赖项相对复杂时,我们将使用它。
-
我们的电子邮件发送器和 pub/sub 发布者被定义为函数。这对于简单的依赖项来说效果很好。
以下是我们在工作中发现自己注入的一些内容
-
一个 S3 文件系统客户端
-
一个键/值存储客户端
-
一个
requests会话对象
其中大多数将具有更复杂的 API,您无法将其捕获为单个函数:读取和写入、GET 和 POST 等等。
即使它很简单,让我们使用 send_mail 作为一个示例来讨论您如何定义更复杂的依赖项。
定义抽象和具体实现
我们将想象一个更通用的通知 API。可能是电子邮件,可能是 SMS,有一天可能是 Slack 帖子。
class AbstractNotifications(abc.ABC):
@abc.abstractmethod
def send(self, destination, message):
raise NotImplementedError
...
class EmailNotifications(AbstractNotifications):
def __init__(self, smtp_host=DEFAULT_HOST, port=DEFAULT_PORT):
self.server = smtplib.SMTP(smtp_host, port=port)
self.server.noop()
def send(self, destination, message):
msg = f"Subject: allocation service notification\n{message}"
self.server.sendmail(
from_addr="allocations@example.com",
to_addrs=[destination],
msg=msg,
)我们更改引导脚本中的依赖项
def bootstrap(
start_orm: bool = True,
uow: unit_of_work.AbstractUnitOfWork = unit_of_work.SqlAlchemyUnitOfWork(),
- send_mail: Callable = email.send,
+ notifications: AbstractNotifications = EmailNotifications(),
publish: Callable = redis_eventpublisher.publish,
) -> messagebus.MessageBus:为您的测试制作一个假版本
我们完成并定义一个用于单元测试的假版本
class FakeNotifications(notifications.AbstractNotifications):
def __init__(self):
self.sent = defaultdict(list) # type: Dict[str, List[str]]
def send(self, destination, message):
self.sent[destination].append(message)
...我们在测试中使用它
def test_sends_email_on_out_of_stock_error(self):
fake_notifs = FakeNotifications()
bus = bootstrap.bootstrap(
start_orm=False,
uow=FakeUnitOfWork(),
notifications=fake_notifs,
publish=lambda *args: None,
)
bus.handle(commands.CreateBatch("b1", "POPULAR-CURTAINS", 9, None))
bus.handle(commands.Allocate("o1", "POPULAR-CURTAINS", 10))
assert fake_notifs.sent["stock@made.com"] == [
f"Out of stock for POPULAR-CURTAINS",
]弄清楚如何集成测试真实的东西
现在我们测试真实的东西,通常使用端到端或集成测试。我们使用了 MailHog 作为我们 Docker 开发环境的真实电子邮件服务器
version: "3"
services:
redis_pubsub:
build:
context: .
dockerfile: Dockerfile
image: allocation-image
...
api:
image: allocation-image
...
postgres:
image: postgres:9.6
...
redis:
image: redis:alpine
...
mailhog:
image: mailhog/mailhog
ports:
- "11025:1025"
- "18025:8025"在我们的集成测试中,我们使用真实的 EmailNotifications 类,与 Docker 集群中的 MailHog 服务器通信
@pytest.fixture
def bus(sqlite_session_factory):
bus = bootstrap.bootstrap(
start_orm=True,
uow=unit_of_work.SqlAlchemyUnitOfWork(sqlite_session_factory),
notifications=notifications.EmailNotifications(), #(1)
publish=lambda *args: None,
)
yield bus
clear_mappers()
def get_email_from_mailhog(sku): #(2)
host, port = map(config.get_email_host_and_port().get, ["host", "http_port"])
all_emails = requests.get(f"http://{host}:{port}/api/v2/messages").json()
return next(m for m in all_emails["items"] if sku in str(m))
def test_out_of_stock_email(bus):
sku = random_sku()
bus.handle(commands.CreateBatch("batch1", sku, 9, None)) #(3)
bus.handle(commands.Allocate("order1", sku, 10))
email = get_email_from_mailhog(sku)
assert email["Raw"]["From"] == "allocations@example.com" #(4)
assert email["Raw"]["To"] == ["stock@made.com"]
assert f"Out of stock for {sku}" in email["Raw"]["Data"]-
我们使用我们的引导启动器来构建一个与真实通知类对话的消息总线。
-
我们弄清楚如何从我们的“真实”电子邮件服务器获取电子邮件。
-
我们使用总线来进行我们的测试设置。
-
出乎意料的是,这实际上奏效了,几乎是一次成功!
这就是全部了。
总结
-
一旦您有多个适配器,您将开始感受到手动传递依赖项带来的很多痛苦,除非您进行某种依赖注入。
-
设置依赖注入只是在启动应用程序时需要执行一次的许多典型设置/初始化活动之一。将所有这些整合到一个引导脚本中通常是一个好主意。
-
引导脚本也适合作为为您的适配器提供合理的默认配置的位置,以及作为使用 fakes 覆盖这些适配器以进行测试的单个位置。
-
如果您发现自己需要在多个级别进行 DI——例如,如果您有组件的链式依赖项,所有这些组件都需要 DI,那么依赖注入框架可能很有用。
-
本章还介绍了一个工作示例,说明如何将隐式/简单依赖项更改为“正确”的适配器,分解出 ABC,定义其实际和假的实现,并考虑集成测试。