
6:工作单元模式
在本章中,我们将介绍最后一块拼图,它将仓库模式和服务层模式结合在一起:工作单元模式。
如果仓库模式是我们对持久化存储概念的抽象,那么工作单元 (UoW) 模式就是我们对原子操作概念的抽象。它将使我们最终且完全地将服务层与数据层解耦。
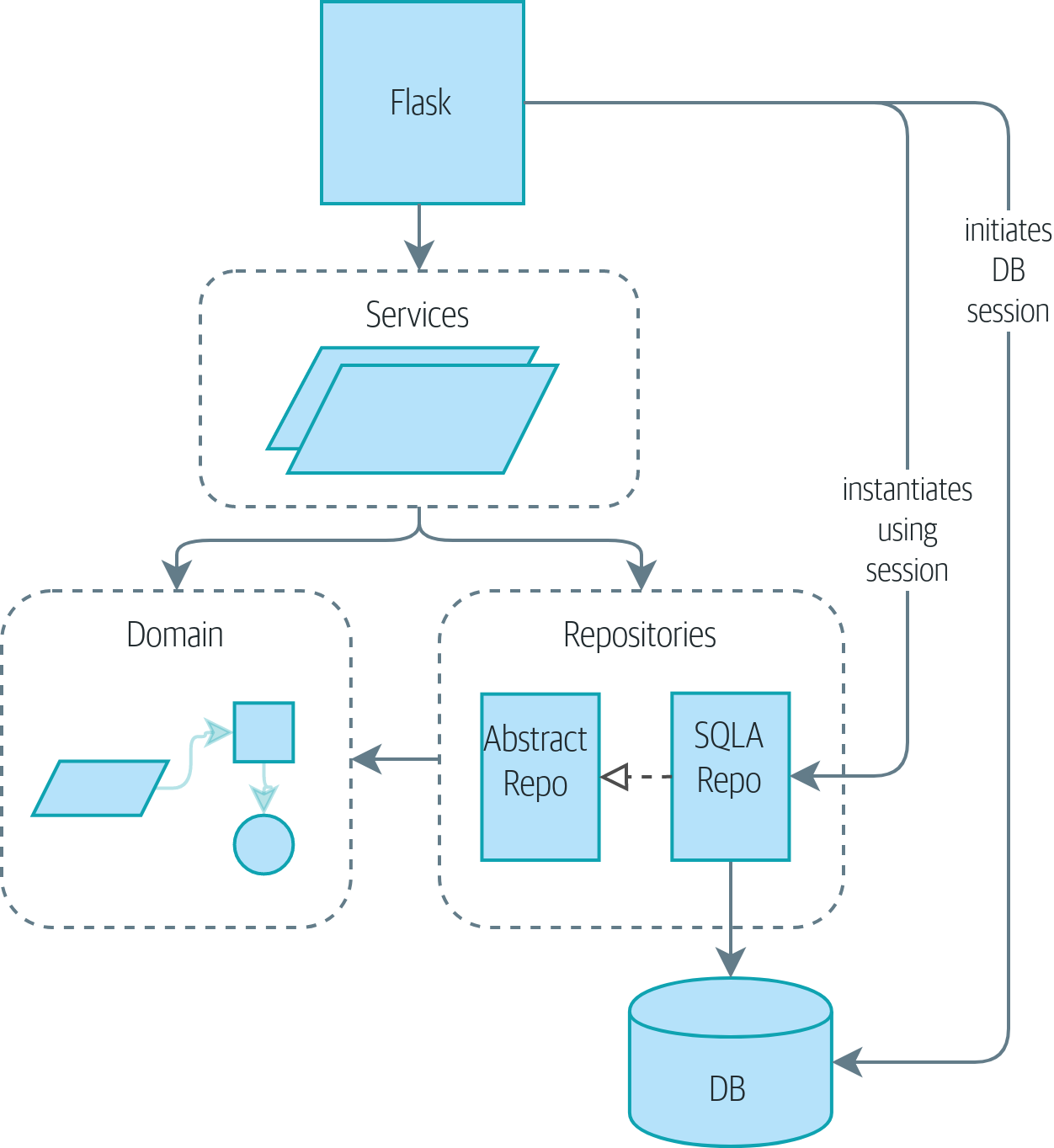
没有 UoW:API 直接与三层对话 表明,目前,我们的基础设施层之间发生了大量的通信:API 直接与数据库层对话以启动会话,它与仓库层对话以初始化 SQLAlchemyRepository,并且它与服务层对话以请求分配。
|
提示
|
本章的代码位于 chapter_06_uow 分支 在 GitHub 上 git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_06_uow # or to code along, checkout Chapter 4: git checkout chapter_04_service_layer |
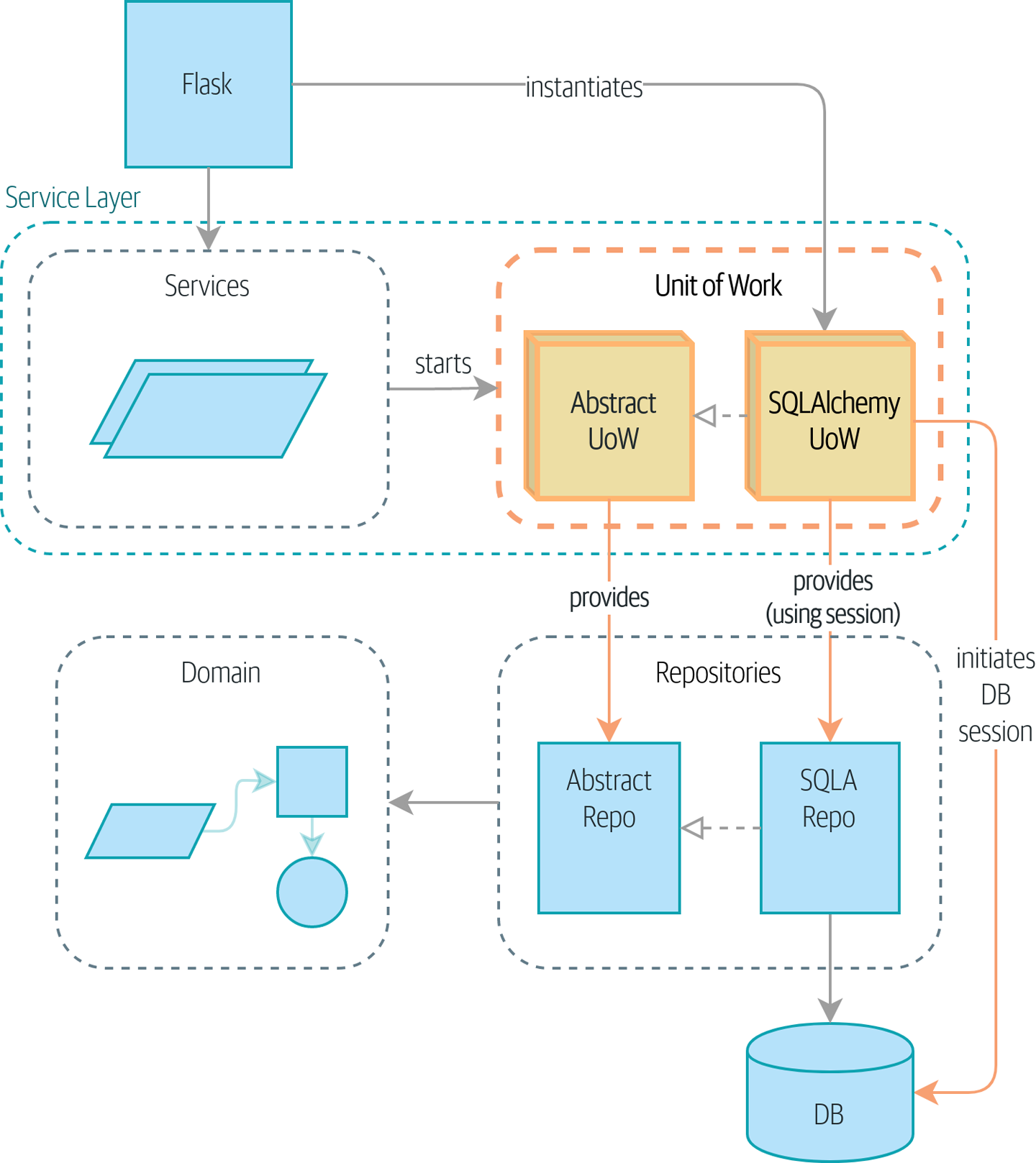
使用 UoW:UoW 现在管理数据库状态 显示了我们的目标状态。Flask API 现在只做两件事:它初始化一个工作单元,并调用一个服务。该服务与 UoW 协作(我们喜欢将 UoW 视为服务层的一部分),但服务函数本身和 Flask 都不再需要直接与数据库对话。
我们将使用一段可爱的 Python 语法来完成这一切,一个上下文管理器。
工作单元与仓库协作
让我们看看工作单元(或 UoW,我们发音为 "you-wow")是如何运作的。以下是完成后的服务层的外观
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork,
) -> str:
line = OrderLine(orderid, sku, qty)
with uow: #(1)
batches = uow.batches.list() #(2)
...
batchref = model.allocate(line, batches)
uow.commit() #(3)-
我们将启动一个 UoW 作为上下文管理器。
-
uow.batches是批次仓库,因此 UoW 为我们提供了对永久存储的访问。 -
当我们完成时,我们使用 UoW 提交或回滚我们的工作。
UoW 充当我们持久化存储的单个入口点,并且它跟踪已加载的对象和最新状态。[1]
这为我们提供了三个有用的东西
-
数据库的稳定快照,以便我们使用的对象在操作过程中不会发生变化
-
一种一次性持久化我们所有更改的方法,这样如果出现问题,我们不会最终处于不一致的状态
-
一个简单的 API 来处理我们的持久化问题,以及一个方便获取仓库的地方
使用集成测试测试驱动 UoW
以下是我们针对 UOW 的集成测试
def test_uow_can_retrieve_a_batch_and_allocate_to_it(session_factory):
session = session_factory()
insert_batch(session, "batch1", "HIPSTER-WORKBENCH", 100, None)
session.commit()
uow = unit_of_work.SqlAlchemyUnitOfWork(session_factory) #(1)
with uow:
batch = uow.batches.get(reference="batch1") #(2)
line = model.OrderLine("o1", "HIPSTER-WORKBENCH", 10)
batch.allocate(line)
uow.commit() #(3)
batchref = get_allocated_batch_ref(session, "o1", "HIPSTER-WORKBENCH")
assert batchref == "batch1"-
我们通过使用自定义会话工厂初始化 UoW,并返回一个
uow对象以在我们的with代码块中使用。 -
UoW 通过
uow.batches为我们提供对批次仓库的访问。 -
当我们完成时,我们调用它的
commit()。
对于好奇的人,insert_batch 和 get_allocated_batch_ref 助手看起来像这样
def insert_batch(session, ref, sku, qty, eta):
session.execute(
"INSERT INTO batches (reference, sku, _purchased_quantity, eta)"
" VALUES (:ref, :sku, :qty, :eta)",
dict(ref=ref, sku=sku, qty=qty, eta=eta),
)
def get_allocated_batch_ref(session, orderid, sku):
[[orderlineid]] = session.execute( #(1)
"SELECT id FROM order_lines WHERE orderid=:orderid AND sku=:sku",
dict(orderid=orderid, sku=sku),
)
[[batchref]] = session.execute( #(1)
"SELECT b.reference FROM allocations JOIN batches AS b ON batch_id = b.id"
" WHERE orderline_id=:orderlineid",
dict(orderlineid=orderlineid),
)
return batchref工作单元及其上下文管理器
在我们的测试中,我们隐式地定义了 UoW 需要执行的操作的接口。让我们通过使用抽象基类来显式地定义它
class AbstractUnitOfWork(abc.ABC):
batches: repository.AbstractRepository #(1)
def __exit__(self, *args): #(2)
self.rollback() #(4)
@abc.abstractmethod
def commit(self): #(3)
raise NotImplementedError
@abc.abstractmethod
def rollback(self): #(4)
raise NotImplementedError-
UoW 提供一个名为
.batches的属性,它将为我们提供对批次仓库的访问。 -
如果您从未见过上下文管理器,
__enter__和__exit__是两个魔术方法,它们分别在我们进入with代码块和退出代码块时执行。它们是我们的设置和拆卸阶段。 -
当我们准备好时,我们将调用此方法来显式提交我们的工作。
-
如果我们不提交,或者如果我们通过引发错误退出上下文管理器,我们将执行
rollback。(如果已调用commit(),则回滚无效。请继续阅读以了解更多讨论。)
真实的工作单元使用 SQLAlchemy 会话
我们的具体实现添加的主要内容是数据库会话
DEFAULT_SESSION_FACTORY = sessionmaker( #(1)
bind=create_engine(
config.get_postgres_uri(),
)
)
class SqlAlchemyUnitOfWork(AbstractUnitOfWork):
def __init__(self, session_factory=DEFAULT_SESSION_FACTORY):
self.session_factory = session_factory #(1)
def __enter__(self):
self.session = self.session_factory() # type: Session #(2)
self.batches = repository.SqlAlchemyRepository(self.session) #(2)
return super().__enter__()
def __exit__(self, *args):
super().__exit__(*args)
self.session.close() #(3)
def commit(self): #(4)
self.session.commit()
def rollback(self): #(4)
self.session.rollback()-
该模块定义了一个默认会话工厂,它将连接到 Postgres,但我们允许在集成测试中覆盖它,以便我们可以改用 SQLite。
-
__enter__方法负责启动数据库会话并实例化可以使用该会话的真实仓库。 -
我们在退出时关闭会话。
-
最后,我们提供了具体的
commit()和rollback()方法,它们使用我们的数据库会话。
用于测试的伪造工作单元
以下是我们在服务层测试中如何使用伪造 UoW
class FakeUnitOfWork(unit_of_work.AbstractUnitOfWork):
def __init__(self):
self.batches = FakeRepository([]) #(1)
self.committed = False #(2)
def commit(self):
self.committed = True #(2)
def rollback(self):
pass
def test_add_batch():
uow = FakeUnitOfWork() #(3)
services.add_batch("b1", "CRUNCHY-ARMCHAIR", 100, None, uow) #(3)
assert uow.batches.get("b1") is not None
assert uow.committed
def test_allocate_returns_allocation():
uow = FakeUnitOfWork() #(3)
services.add_batch("batch1", "COMPLICATED-LAMP", 100, None, uow) #(3)
result = services.allocate("o1", "COMPLICATED-LAMP", 10, uow) #(3)
assert result == "batch1"
...-
FakeUnitOfWork和FakeRepository紧密耦合,就像真实的UnitofWork和Repository类一样。这很好,因为我们认识到这些对象是协作者。 -
请注意与
FakeSession中的伪造commit()函数的相似之处(我们现在可以摆脱它了)。但这有很大的改进,因为我们现在伪造的是我们自己编写的代码,而不是第三方代码。有人说,“不要模拟你不拥有的东西”。 -
在我们的测试中,我们可以实例化一个 UoW 并将其传递给我们的服务层,而不是传递仓库和会话。这要方便得多。
在服务层中使用 UoW
以下是我们的新服务层的外观
def add_batch(
ref: str, sku: str, qty: int, eta: Optional[date],
uow: unit_of_work.AbstractUnitOfWork, #(1)
):
with uow:
uow.batches.add(model.Batch(ref, sku, qty, eta))
uow.commit()
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork, #(1)
) -> str:
line = OrderLine(orderid, sku, qty)
with uow:
batches = uow.batches.list()
if not is_valid_sku(line.sku, batches):
raise InvalidSku(f"Invalid sku {line.sku}")
batchref = model.allocate(line, batches)
uow.commit()
return batchref-
我们的服务层现在只有一个依赖项,再次依赖于抽象 UoW。
提交/回滚行为的显式测试
为了使我们自己相信提交/回滚行为有效,我们编写了几个测试
def test_rolls_back_uncommitted_work_by_default(session_factory):
uow = unit_of_work.SqlAlchemyUnitOfWork(session_factory)
with uow:
insert_batch(uow.session, "batch1", "MEDIUM-PLINTH", 100, None)
new_session = session_factory()
rows = list(new_session.execute('SELECT * FROM "batches"'))
assert rows == []
def test_rolls_back_on_error(session_factory):
class MyException(Exception):
pass
uow = unit_of_work.SqlAlchemyUnitOfWork(session_factory)
with pytest.raises(MyException):
with uow:
insert_batch(uow.session, "batch1", "LARGE-FORK", 100, None)
raise MyException()
new_session = session_factory()
rows = list(new_session.execute('SELECT * FROM "batches"'))
assert rows == []|
提示
|
我们没有在此处展示它,但值得针对“真实”数据库(即相同的引擎)测试一些更“晦涩”的数据库行为,例如事务。目前,我们正在使用 SQLite 而不是 Postgres,但在 [chapter_07_aggregate] 中,我们将把一些测试切换为使用真实数据库。我们的 UoW 类使其变得容易,这真是太方便了! |
显式与隐式提交
现在我们简要地讨论一下实现 UoW 模式的不同方法。
我们可以想象一个略有不同的 UoW 版本,它默认提交,并且仅在发现异常时才回滚
class AbstractUnitOfWork(abc.ABC):
def __enter__(self):
return self
def __exit__(self, exn_type, exn_value, traceback):
if exn_type is None:
self.commit() #(1)
else:
self.rollback() #(2)-
我们应该在 happy path 中使用隐式提交吗?
-
并且仅在异常时回滚?
这将使我们能够节省一行代码,并从我们的客户端代码中删除显式提交
def add_batch(ref: str, sku: str, qty: int, eta: Optional[date], uow):
with uow:
uow.batches.add(model.Batch(ref, sku, qty, eta))
# uow.commit()这是一个判断性调用,但我们倾向于更喜欢要求显式提交,以便我们必须选择何时刷新状态。
尽管我们使用了一行额外的代码,但这使得软件默认是安全的。默认行为是不更改任何内容。反过来,这使我们的代码更容易推理,因为只有一条代码路径会导致系统中的更改:完全成功和显式提交。任何其他代码路径、任何异常、从 UoW 范围的任何提前退出都会导致安全状态。
同样,我们更喜欢默认回滚,因为它更容易理解;这将回滚到上次提交,因此要么用户执行了一次提交,要么我们清除了他们的更改。苛刻但简单。
示例:使用 UoW 将多个操作分组到原子单元中
以下是一些示例,展示了工作单元模式的用法。您可以看到它如何导致对哪些代码块一起发生进行简单的推理。
示例 1:重新分配
假设我们希望能够取消分配然后重新分配订单
def reallocate(
line: OrderLine,
uow: AbstractUnitOfWork,
) -> str:
with uow:
batch = uow.batches.get(sku=line.sku)
if batch is None:
raise InvalidSku(f'Invalid sku {line.sku}')
batch.deallocate(line) #(1)
allocate(line) #(2)
uow.commit()-
如果
deallocate()失败,我们显然不想调用allocate()。 -
如果
allocate()失败,我们可能也不想实际提交deallocate()。
示例 2:更改批次数量
我们的航运公司打电话给我们说,其中一个集装箱门打开了,我们一半的沙发掉进了印度洋。糟糕!
def change_batch_quantity(
batchref: str, new_qty: int,
uow: AbstractUnitOfWork,
):
with uow:
batch = uow.batches.get(reference=batchref)
batch.change_purchased_quantity(new_qty)
while batch.available_quantity < 0:
line = batch.deallocate_one() #(1)
uow.commit()-
在这里,我们可能需要取消分配任意数量的行。如果我们在任何阶段遇到故障,我们可能希望不提交任何更改。
整理集成测试
我们现在有三组测试,所有测试本质上都指向数据库:test_orm.py、test_repository.py 和 test_uow.py。我们应该扔掉哪些?
└── tests
├── conftest.py
├── e2e
│ └── test_api.py
├── integration
│ ├── test_orm.py
│ ├── test_repository.py
│ └── test_uow.py
├── pytest.ini
└── unit
├── test_allocate.py
├── test_batches.py
└── test_services.py如果您认为测试从长远来看不会增加价值,您应该始终可以随意扔掉测试。我们会说 test_orm.py 主要是一个帮助我们学习 SQLAlchemy 的工具,因此从长远来看我们不需要它,特别是如果它正在做的主要事情在 test_repository.py 中得到了涵盖。最后一个测试,您可能会保留,但我们当然可以找到一个论点来证明将所有内容都保持在尽可能高的抽象级别(就像我们在单元测试中所做的那样)。
|
提示
|
这是 [chapter_05_high_gear_low_gear] 中的课程的另一个例子:当我们构建更好的抽象时,我们可以将我们的测试转移到针对它们运行,这使我们可以自由地更改底层的细节。 |
总结
希望我们已经说服您,工作单元模式很有用,并且上下文管理器是一种非常好的 Pythonic 方式,可以直观地将代码分组到我们希望原子性发生的块中。
事实上,这种模式非常有用,以至于 SQLAlchemy 已经以 Session 对象的形式使用了 UoW。SQLAlchemy 中的 Session 对象是您的应用程序从数据库加载数据的方式。
每次您从数据库加载新实体时,会话都会开始跟踪对实体的更改,并且当会话刷新时,您的所有更改都会一起持久化。如果 SQLAlchemy 会话已经实现了我们想要的模式,为什么我们还要费力地抽象掉 SQLAlchemy 会话呢?
工作单元模式:权衡 讨论了一些权衡。
| 优点 | 缺点 |
|---|---|
|
|
首先,Session API 功能丰富,并支持我们不希望或不需要在我们的领域中进行的操作。我们的 UnitOfWork 将会话简化为它的基本核心:它可以启动、提交或丢弃。
另一方面,我们正在使用 UnitOfWork 来访问我们的 Repository 对象。这是一个简洁的开发人员可用性,我们无法使用普通的 SQLAlchemy Session 来实现。
最后,我们再次受到依赖倒置原则的驱动:我们的服务层依赖于一个薄抽象,我们在系统的外部边缘附加一个具体的实现。这与 SQLAlchemy 自己的 建议 非常吻合
保持会话(通常是事务)的生命周期分离和外部化。对于更重要的应用程序,最全面的方法(推荐)将尝试将会话、事务和异常管理的细节尽可能地远离执行其工作的程序的细节。