
12:命令查询职责分离 (CQRS)
在本章中,我们将从一个相当不具争议的见解开始:读取(查询)和写入(命令)是不同的,因此它们应该被区别对待(或者如果愿意,可以分离它们的职责)。然后,我们将尽可能地推进这个见解。
如果你和 Harry 一样,起初这一切都会显得很极端,但希望我们能够论证它并非完全不合理。
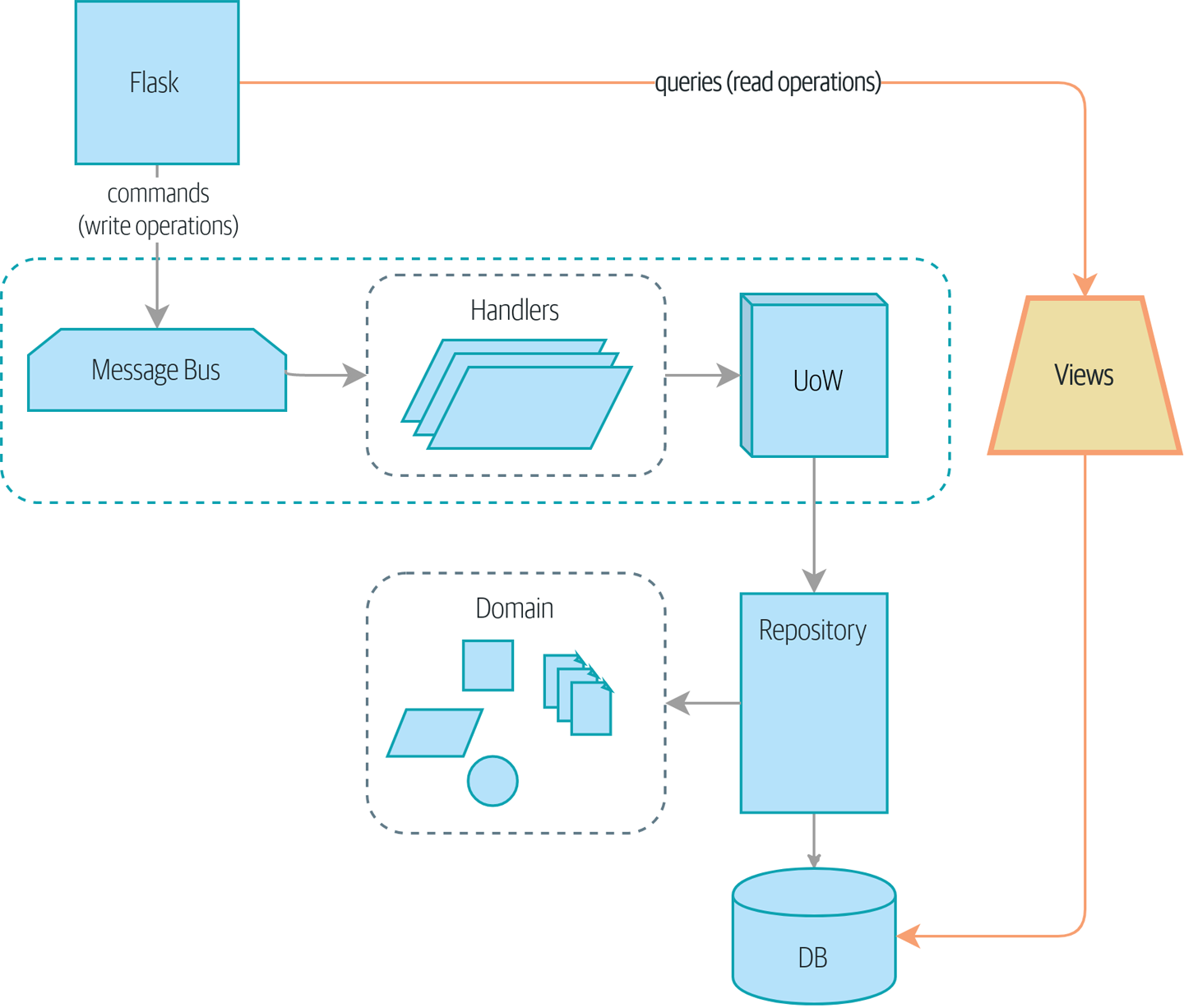
将读取与写入分离 展示了我们最终可能达到的目标。
|
提示
|
本章的代码位于 chapter_12_cqrs 分支 在 GitHub 上。 git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_12_cqrs # or to code along, checkout the previous chapter: git checkout chapter_11_external_events |
不过,首先,为什么要费心呢?
领域模型用于写入
本书的大部分时间都在讨论如何构建软件来执行我们领域的规则。这些规则或约束,对于每个应用程序都将是不同的,并且它们构成了我们系统的有趣核心。
在本书中,我们设置了明确的约束,例如“你不能分配超过可用库存的量”,以及隐含的约束,例如“每个订单行都分配给一个批次。”
我们在本书的开头将这些规则写成了单元测试
def test_allocating_to_a_batch_reduces_the_available_quantity():
batch = Batch("batch-001", "SMALL-TABLE", qty=20, eta=date.today())
line = OrderLine("order-ref", "SMALL-TABLE", 2)
batch.allocate(line)
assert batch.available_quantity == 18
...
def test_cannot_allocate_if_available_smaller_than_required():
small_batch, large_line = make_batch_and_line("ELEGANT-LAMP", 2, 20)
assert small_batch.can_allocate(large_line) is False为了正确应用这些规则,我们需要确保操作是一致的,因此我们引入了工作单元和聚合等模式,以帮助我们提交小块工作。
为了在这些小块之间传递更改,我们引入了领域事件模式,以便我们可以编写诸如“当库存损坏或丢失时,调整批次的可用数量,并在必要时重新分配订单”之类的规则。
所有这些复杂性都存在,以便我们可以在更改系统状态时执行规则。我们构建了一套灵活的工具用于写入数据。
但是读取呢?
大多数用户不会购买你的家具
在 MADE.com,我们有一个非常类似于分配服务的系统。在繁忙的一天中,我们可能每小时处理一百个订单,并且我们有一个庞大而复杂的系统用于将库存分配给这些订单。
但在同一繁忙的一天中,我们可能每秒有 100 次产品浏览量。每次有人访问产品页面或产品列表页面时,我们需要弄清楚产品是否仍有库存以及交付需要多长时间。
领域是相同的——我们关注的是库存批次,以及它们的到货日期,以及仍然可用的数量——但访问模式却截然不同。例如,如果查询延迟几秒钟,我们的客户不会注意到,但如果我们的分配服务不一致,我们将把他们的订单搞得一团糟。我们可以利用这种差异,使我们的读取最终一致,从而提高性能。
我们可以将这些需求视为构成系统两个部分:读取端和写入端,如读取与写入对比所示。
对于写入端,我们精巧的领域架构模式帮助我们随着时间的推移发展我们的系统,但是我们目前为止构建的复杂性对于读取数据没有任何好处。服务层、工作单元和巧妙的领域模型只是累赘。
| 读取端 | 写入端 | |
|---|---|---|
行为 |
简单读取 |
复杂业务逻辑 |
可缓存性 |
高度可缓存 |
不可缓存 |
一致性 |
可以过时 |
必须是事务性一致的 |
Post/Redirect/Get 和 CQS
如果你做 Web 开发,你可能熟悉 Post/Redirect/Get 模式。在这种技术中,Web 端点接受 HTTP POST 并响应重定向以查看结果。例如,我们可能接受对 /batches 的 POST 请求以创建新批次,并将用户重定向到 /batches/123 以查看他们新创建的批次。
这种方法解决了用户刷新浏览器中的结果页面或尝试将结果页面添加到书签时出现的问题。在刷新的情况下,它可能导致我们的用户重复提交数据,从而在他们只需要一个沙发时购买了两个。在书签的情况下,我们不幸的客户在尝试 GET 一个 POST 端点时最终会得到一个损坏的页面。
这些问题都发生的原因是我们在响应写入操作时返回数据。Post/Redirect/Get 通过分离操作的读取和写入阶段来规避这个问题。
这种技术是命令查询分离 (CQS) 的一个简单示例。[1] 我们遵循一个简单的规则:函数应该修改状态或回答问题,但永远不要两者兼而有之。这使得软件更容易推理:我们应该始终能够问“灯亮了吗?”而不会拨动灯开关。
|
注意
|
在构建 API 时,我们可以应用相同的设计技术,通过返回 201 Created 或 202 Accepted,并在 Location 标头中包含我们新资源的 URI。这里重要的是不是我们使用的状态代码,而是将工作逻辑分离为写入阶段和查询阶段。 |
正如你将看到的,我们可以使用 CQS 原则来使我们的系统更快、更可扩展,但首先,让我们修复现有代码中的 CQS 违规。很久以前,我们引入了一个 allocate 端点,它接受一个订单并调用我们的服务层来分配一些库存。在调用的最后,我们返回 200 OK 和批次 ID。这导致了一些丑陋的设计缺陷,以便我们可以获得我们需要的数据。让我们将其更改为返回简单的 OK 消息,而是提供一个新的只读端点来检索分配状态
@pytest.mark.usefixtures("postgres_db")
@pytest.mark.usefixtures("restart_api")
def test_happy_path_returns_202_and_batch_is_allocated():
orderid = random_orderid()
sku, othersku = random_sku(), random_sku("other")
earlybatch = random_batchref(1)
laterbatch = random_batchref(2)
otherbatch = random_batchref(3)
api_client.post_to_add_batch(laterbatch, sku, 100, "2011-01-02")
api_client.post_to_add_batch(earlybatch, sku, 100, "2011-01-01")
api_client.post_to_add_batch(otherbatch, othersku, 100, None)
r = api_client.post_to_allocate(orderid, sku, qty=3)
assert r.status_code == 202
r = api_client.get_allocation(orderid)
assert r.ok
assert r.json() == [
{"sku": sku, "batchref": earlybatch},
]
@pytest.mark.usefixtures("postgres_db")
@pytest.mark.usefixtures("restart_api")
def test_unhappy_path_returns_400_and_error_message():
unknown_sku, orderid = random_sku(), random_orderid()
r = api_client.post_to_allocate(
orderid, unknown_sku, qty=20, expect_success=False
)
assert r.status_code == 400
assert r.json()["message"] == f"Invalid sku {unknown_sku}"
r = api_client.get_allocation(orderid)
assert r.status_code == 404好的,Flask 应用程序可能是什么样子?
from allocation import views
...
@app.route("/allocations/<orderid>", methods=["GET"])
def allocations_view_endpoint(orderid):
uow = unit_of_work.SqlAlchemyUnitOfWork()
result = views.allocations(orderid, uow) #(1)
if not result:
return "not found", 404
return jsonify(result), 200-
好的,一个 views.py,没问题;我们可以将只读的东西放在那里,它将是一个真正的 views.py,不像 Django 的,它可以知道如何构建我们数据的只读视图……
伙计们,请稳住!
嗯,所以我们可能只需在现有的仓库对象中添加一个列表方法
from allocation.service_layer import unit_of_work
def allocations(orderid: str, uow: unit_of_work.SqlAlchemyUnitOfWork):
with uow:
results = uow.session.execute(
"""
SELECT ol.sku, b.reference
FROM allocations AS a
JOIN batches AS b ON a.batch_id = b.id
JOIN order_lines AS ol ON a.orderline_id = ol.id
WHERE ol.orderid = :orderid
""",
dict(orderid=orderid),
)
return [{"sku": sku, "batchref": batchref} for sku, batchref in results]打扰一下?原始 SQL?
如果你和 Harry 一样第一次遇到这种模式,你可能会想知道 Bob 到底吸了什么。我们现在要手动编写自己的 SQL,并将数据库行直接转换为字典?在我们为构建一个优秀的领域模型付出了所有努力之后?仓库模式呢?那不是应该作为我们数据库周围的抽象层吗?为什么我们不重用它呢?
好吧,让我们首先探索一下这个看似更简单的替代方案,看看它在实践中是什么样子。
我们仍然会将视图保留在单独的 views.py 模块中;在你的应用程序中强制执行读取和写入之间的清晰区分仍然是一个好主意。我们应用命令查询分离,并且很容易看出哪些代码修改状态(事件处理程序)以及哪些代码仅检索只读状态(视图)。
|
提示
|
即使你不想完全采用 CQRS,将只读视图与修改状态的命令和事件处理程序分开可能也是一个好主意。 |
测试 CQRS 视图
在我们深入探讨各种选项之前,让我们谈谈测试。无论你决定采用哪种方法,你可能至少需要一个集成测试。像这样
def test_allocations_view(sqlite_session_factory):
uow = unit_of_work.SqlAlchemyUnitOfWork(sqlite_session_factory)
messagebus.handle(commands.CreateBatch("sku1batch", "sku1", 50, None), uow) #(1)
messagebus.handle(commands.CreateBatch("sku2batch", "sku2", 50, today), uow)
messagebus.handle(commands.Allocate("order1", "sku1", 20), uow)
messagebus.handle(commands.Allocate("order1", "sku2", 20), uow)
# add a spurious batch and order to make sure we're getting the right ones
messagebus.handle(commands.CreateBatch("sku1batch-later", "sku1", 50, today), uow)
messagebus.handle(commands.Allocate("otherorder", "sku1", 30), uow)
messagebus.handle(commands.Allocate("otherorder", "sku2", 10), uow)
assert views.allocations("order1", uow) == [
{"sku": "sku1", "batchref": "sku1batch"},
{"sku": "sku2", "batchref": "sku2batch"},
]-
我们通过使用应用程序的公共入口点(消息总线)来完成集成测试的设置。这使我们的测试与关于事物如何存储的任何实现/基础设施细节解耦。
“显而易见”的替代方案 1:使用现有的仓库
在我们的 products 仓库中添加一个辅助方法怎么样?
from allocation import unit_of_work
def allocations(orderid: str, uow: unit_of_work.AbstractUnitOfWork):
with uow:
products = uow.products.for_order(orderid=orderid) #(1)
batches = [b for p in products for b in p.batches] #(2)
return [
{'sku': b.sku, 'batchref': b.reference}
for b in batches
if orderid in b.orderids #(3)
]-
我们的仓库返回
Product对象,我们需要找到给定订单中 SKU 的所有产品,因此我们将在仓库上构建一个新的辅助方法.for_order()。 -
现在我们有了产品,但实际上我们需要批次引用,因此我们使用列表推导式获取所有可能的批次。
-
我们再次过滤以仅获取特定订单的批次。反过来,这依赖于我们的
Batch对象能够告诉我们它已分配了哪些订单 ID。
我们使用 .orderid 属性实现最后一点
class Batch:
...
@property
def orderids(self):
return {l.orderid for l in self._allocations}你可以开始看到,重用我们现有的仓库和领域模型类并不像你可能假设的那样简单。我们不得不在两者中添加新的辅助方法,并且我们在 Python 中进行了一堆循环和过滤,这些工作本可以在数据库中更有效地完成。
所以,是的,从好的方面来说,我们正在重用我们现有的抽象,但从坏的方面来说,这一切都感觉非常笨拙。
你的领域模型未针对读取操作进行优化
我们在这里看到的是拥有一个主要为写入操作设计的领域模型的效果,而我们对读取的需求在概念上通常完全不同。
这是架构师们为 CQRS 辩护的理由。正如我们之前所说,领域模型不是数据模型——我们试图捕捉业务运作的方式:工作流程、围绕状态更改的规则、交换的消息;关于系统如何对外部事件和用户输入做出反应的关注点。这些东西中的大部分与只读操作完全无关。
|
提示
|
对 CQRS 的这种辩护与对领域模型模式的辩护有关。如果你正在构建一个简单的 CRUD 应用程序,读取和写入将紧密相关,因此你不需要领域模型或 CQRS。但是,你的领域越复杂,你就越有可能同时需要两者。 |
为了提出一个肤浅的观点,你的领域类将具有多个用于修改状态的方法,而你将不需要任何这些方法用于只读操作。
随着领域模型复杂性的增长,你会发现自己在如何构建该模型方面做出越来越多的选择,这使得它越来越难以用于读取操作。
“显而易见”的替代方案 2:使用 ORM
你可能会想,好吧,如果我们的仓库很笨拙,并且使用 Products 很笨拙,那么我至少可以使用我的 ORM 并使用 Batches。这就是它的用途!
from allocation import unit_of_work, model
def allocations(orderid: str, uow: unit_of_work.AbstractUnitOfWork):
with uow:
batches = uow.session.query(model.Batch).join(
model.OrderLine, model.Batch._allocations
).filter(
model.OrderLine.orderid == orderid
)
return [
{"sku": b.sku, "batchref": b.batchref}
for b in batches
]但这实际上比伙计们,请稳住!中的代码示例中的原始 SQL 版本更容易编写或理解吗?它在那里可能看起来还不错,但我们可以告诉你,它花费了几次尝试,并且查阅了大量的 SQLAlchemy 文档。SQL 就是 SQL。
但是 ORM 也可能使我们面临性能问题。
SELECT N+1 和其他性能考虑因素
所谓的 SELECT N+1 问题是 ORM 的常见性能问题:当检索对象列表时,你的 ORM 通常会执行初始查询,例如,获取它需要的所有对象的 ID,然后为每个对象发出单独的查询以检索其属性。如果你的对象上有任何外键关系,则尤其如此。
|
注意
|
公平地说,我们应该说 SQLAlchemy 在避免 SELECT N+1 问题方面做得很好。它在前面的示例中没有显示出来,你可以显式请求 eager loading 以在处理连接对象时避免它。 |
除了 SELECT N+1 之外,你可能有其他原因想要解耦持久化状态更改的方式与检索当前状态的方式。一组完全规范化的关系表是确保写入操作永远不会导致数据损坏的好方法。但是使用大量连接检索数据可能会很慢。在这种情况下,通常会添加一些非规范化的视图,构建读取副本,甚至添加缓存层。
是时候彻底跳出框架了
关于这一点:我们是否说服你,我们的原始 SQL 版本不像最初看起来那么奇怪?也许我们是为了效果而夸大其词?等着瞧。
所以,不管是否合理,那个硬编码的 SQL 查询都很丑陋,对吧?如果我们让它更好看呢……
def allocations(orderid: str, uow: unit_of_work.SqlAlchemyUnitOfWork):
with uow:
results = uow.session.execute(
"""
SELECT sku, batchref FROM allocations_view WHERE orderid = :orderid
""",
dict(orderid=orderid),
)
...……通过为我们的视图模型保留一个完全独立的、非规范化的数据存储?
allocations_view = Table(
"allocations_view",
metadata,
Column("orderid", String(255)),
Column("sku", String(255)),
Column("batchref", String(255)),
)好的,更美观的 SQL 查询并不是任何事情的理由,但是构建一个针对读取操作优化的非规范化数据副本并不罕见,一旦你达到了索引可以实现的极限。
即使使用经过良好调整的索引,关系数据库也使用大量 CPU 来执行连接。最快的查询将始终是 SELECT * from mytable WHERE key = :value。
然而,除了原始速度之外,这种方法还为我们带来了规模。当我们向关系数据库写入数据时,我们需要确保我们获得了对我们正在更改的行的锁定,这样我们就不会遇到一致性问题。
如果多个客户端同时更改数据,我们将遇到奇怪的竞争条件。但是,当我们读取数据时,可以并发执行的客户端数量没有限制。因此,只读存储可以水平扩展。
|
提示
|
由于读取副本可能不一致,因此我们可以拥有的副本数量没有限制。如果你正在努力扩展具有复杂数据存储的系统,请问问自己是否可以构建一个更简单的读取模型。 |
保持读取模型更新是一个挑战!数据库视图(物化或其他方式)和触发器是一种常见的解决方案,但这会将你限制在数据库中。我们想向你展示如何重用我们的事件驱动架构。
使用事件处理程序更新读取模型表
我们为 Allocated 事件添加了第二个处理程序
EVENT_HANDLERS = {
events.Allocated: [
handlers.publish_allocated_event,
handlers.add_allocation_to_read_model,
],这是我们的更新视图模型的代码的样子
def add_allocation_to_read_model(
event: events.Allocated,
uow: unit_of_work.SqlAlchemyUnitOfWork,
):
with uow:
uow.session.execute(
"""
INSERT INTO allocations_view (orderid, sku, batchref)
VALUES (:orderid, :sku, :batchref)
""",
dict(orderid=event.orderid, sku=event.sku, batchref=event.batchref),
)
uow.commit()信不信由你,这几乎可以工作!并且它将与我们其余选项的完全相同的集成测试一起工作。
好的,你还需要处理 Deallocated
events.Deallocated: [
handlers.remove_allocation_from_read_model,
handlers.reallocate
],
...
def remove_allocation_from_read_model(
event: events.Deallocated,
uow: unit_of_work.SqlAlchemyUnitOfWork,
):
with uow:
uow.session.execute(
"""
DELETE FROM allocations_view
WHERE orderid = :orderid AND sku = :sku
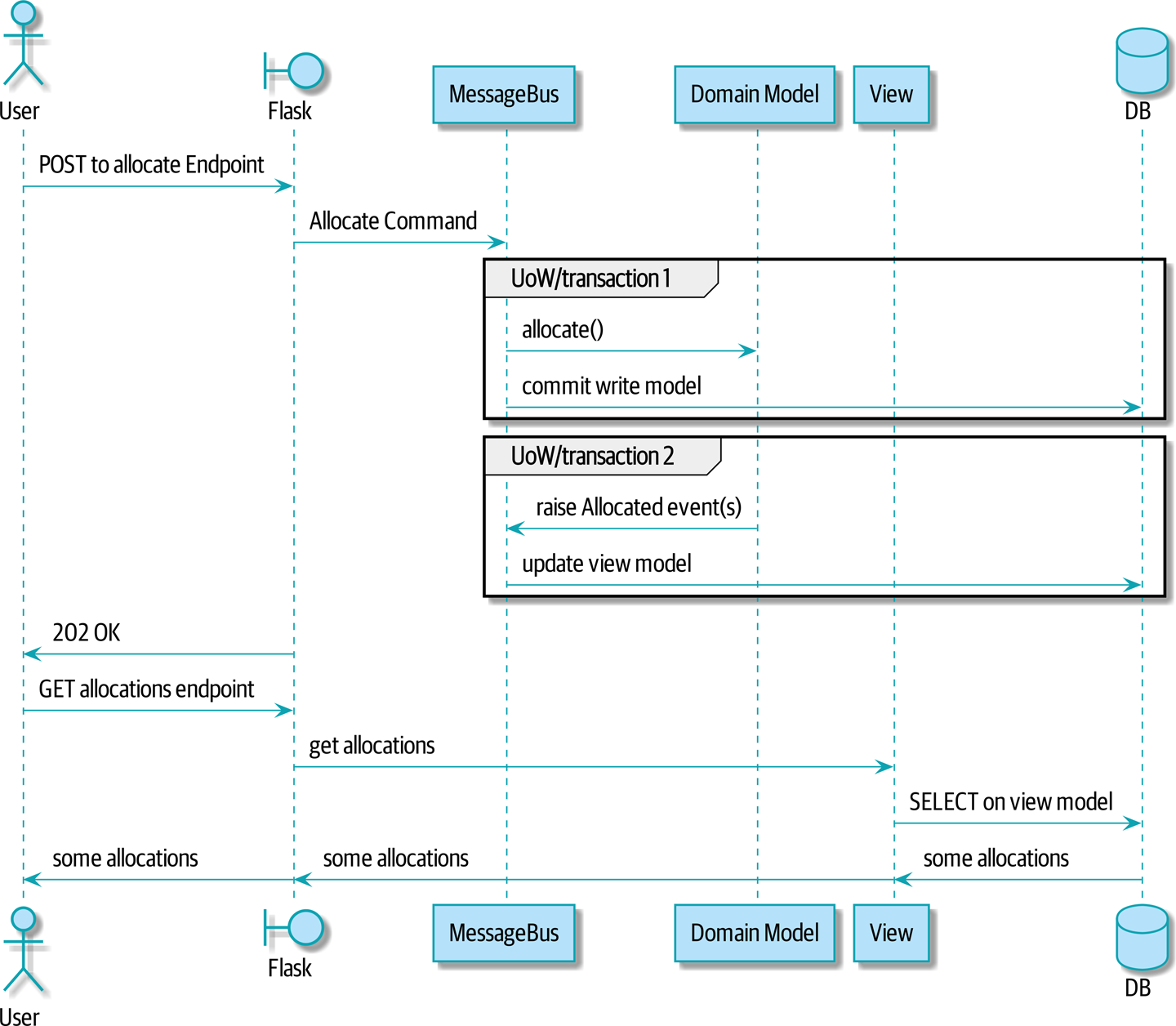
...读取模型序列图 显示了跨两个请求的流程。
[plantuml, apwp_1202, config=plantuml.cfg]
@startuml
scale 4
!pragma teoz true
actor User order 1
boundary Flask order 2
participant MessageBus order 3
participant "Domain Model" as Domain order 4
participant View order 9
database DB order 10
User -> Flask: POST to allocate Endpoint
Flask -> MessageBus : Allocate Command
group UoW/transaction 1
MessageBus -> Domain : allocate()
MessageBus -> DB: commit write model
end
group UoW/transaction 2
Domain -> MessageBus : raise Allocated event(s)
MessageBus -> DB : update view model
end
Flask -> User: 202 OK
User -> Flask: GET allocations endpoint
Flask -> View: get allocations
View -> DB: SELECT on view model
DB -> View: some allocations
& View -> Flask: some allocations
& Flask -> User: some allocations
@enduml
在读取模型序列图中,你可以看到 POST/写入操作中的两个事务,一个用于更新写入模型,另一个用于更新读取模型,GET/读取操作可以使用读取模型。
更改我们的读取模型实现很容易
让我们看看我们的事件驱动模型在行动中带来的灵活性,看看如果我们决定使用完全独立的存储引擎 Redis 来实现读取模型会发生什么。
只需观看
def add_allocation_to_read_model(event: events.Allocated, _):
redis_eventpublisher.update_readmodel(event.orderid, event.sku, event.batchref)
def remove_allocation_from_read_model(event: events.Deallocated, _):
redis_eventpublisher.update_readmodel(event.orderid, event.sku, None)我们 Redis 模块中的助手是一行代码
def update_readmodel(orderid, sku, batchref):
r.hset(orderid, sku, batchref)
def get_readmodel(orderid):
return r.hgetall(orderid)(也许名称 redis_eventpublisher.py 现在用词不当,但你明白了。)
视图本身的变化非常小,以适应其新的后端
def allocations(orderid: str):
batches = redis_eventpublisher.get_readmodel(orderid)
return [
{"batchref": b.decode(), "sku": s.decode()}
for s, b in batches.items()
]并且我们之前拥有的完全相同的集成测试仍然通过,因为它们是在一个抽象级别编写的,该级别与实现解耦:设置将消息放在消息总线上,并且断言是针对我们的视图的。
|
提示
|
如果你决定需要一个读取模型,事件处理程序是管理读取模型更新的好方法。它们还使以后更改该读取模型的实现变得容易。 |
总结
各种视图模型选项的权衡 提出了我们每个选项的一些优点和缺点。
碰巧的是,MADE.com 的分配服务确实使用了“成熟的” CQRS,其读取模型存储在 Redis 中,甚至还有 Varnish 提供的第二层缓存。但它的用例与我们这里展示的用例有很大不同。对于我们正在构建的那种分配服务,似乎不太可能需要使用单独的读取模型和事件处理程序来更新它。
但是,随着你的领域模型变得更加丰富和复杂,简化的读取模型变得越来越有吸引力。
| 选项 | 优点 | 缺点 |
|---|---|---|
仅使用仓库 |
简单、一致的方法。 |
预期复杂查询模式会出现性能问题。 |
使用 ORM 的自定义查询 |
允许重用数据库配置和模型定义。 |
添加另一种具有自身怪癖和语法的查询语言。 |
使用手写 SQL 查询你的普通模型表 |
使用标准查询语法提供对性能的精细控制。 |
数据库架构的更改必须应用于你的手写查询和你的 ORM 定义。高度规范化的架构可能仍然存在性能限制。 |
在你的数据库中添加一些额外的(非规范化的)表作为读取模型 |
非规范化的表可以更快地查询。如果我们在同一事务中更新规范化表和非规范化表,我们将仍然具有良好的数据一致性保证 |
它会稍微减慢写入速度 |
使用事件创建单独的读取存储 |
只读副本易于横向扩展。视图可以在数据更改时构建,以便查询尽可能简单。 |
复杂的技术。Harry 将永远怀疑你的品味和动机。 |
通常,你的读取操作将作用于与你的写入模型相同的概念对象,因此使用 ORM,向你的仓库添加一些读取方法,并将领域模型类用于你的读取操作完全没问题。
在我们的书示例中,读取操作作用于与我们的领域模型完全不同的概念实体。分配服务以单个 SKU 的 Batches 为单位进行思考,但用户关心整个订单的分配,其中包含多个 SKU,因此使用 ORM 最终会有些笨拙。我们很想采用我们在本章开头展示的原始 SQL 视图。
关于这一点,让我们继续进入我们的最后一章。