
尾声:尾声
现在怎么办?
哎哟!我们在这本书中涵盖了很多内容,对于我们的大多数读者来说,所有这些想法都是新的。考虑到这一点,我们不能指望让您成为这些技术的专家。我们真正能做的只是向您展示大致的想法,以及足够的代码,让您继续从头开始编写一些东西。
本书中展示的代码不是经过实战考验的生产代码:它是一组乐高积木,您可以用来搭建您的第一栋房子、宇宙飞船和摩天大楼。
这给我们留下了两个重要的任务。我们想谈谈如何在现有系统中真正开始应用这些想法,并且我们需要警告您一些我们不得不跳过的事情。我们给了您一套全新的自掘坟墓的方法,所以我们应该讨论一些基本的枪支安全知识。
我如何从这里到达那里?
很可能你们中的很多人都在想这样的事情
“好的,Bob 和 Harry,这一切都很好,如果我被聘用从事一个全新的绿地服务,我知道该怎么做。但与此同时,我在这里处理我那团巨大的 Django 泥潭,我看不出任何方法可以到达你们那种漂亮、干净、完美、未受污染、简单的模型。从这里不可能。”
我们听到了您的声音。一旦您已经构建了一团巨大的泥潭,就很难知道如何开始改进。实际上,我们需要逐步解决问题。
首先要弄清楚:您要解决什么问题?软件是否太难更改?性能是否无法接受?您是否有奇怪、莫名其妙的错误?
心中有一个明确的目标将有助于您确定需要完成的工作的优先级,更重要的是,将这样做的理由传达给团队的其他成员。企业往往对技术债务和重构采取务实的态度,只要工程师能够为修复问题提出合理的论据。
|
提示
|
如果您将其与功能工作联系起来,则对系统进行复杂更改通常更容易推销。也许您正在推出新产品或向新市场开放您的服务?现在是花费工程资源来修复基础架构的正确时机。对于一个为期六个月的交付项目,更容易为三周的清理工作提出论据。Bob 将此称为架构税。 |
分离纠缠的职责
在本书的开头,我们说过,一团巨大的泥潭的主要特征是同质性:系统的每个部分看起来都一样,因为我们没有明确每个组件的职责。为了解决这个问题,我们需要开始分离职责并引入清晰的边界。我们可以做的第一件事是开始构建服务层(协作系统的领域)。
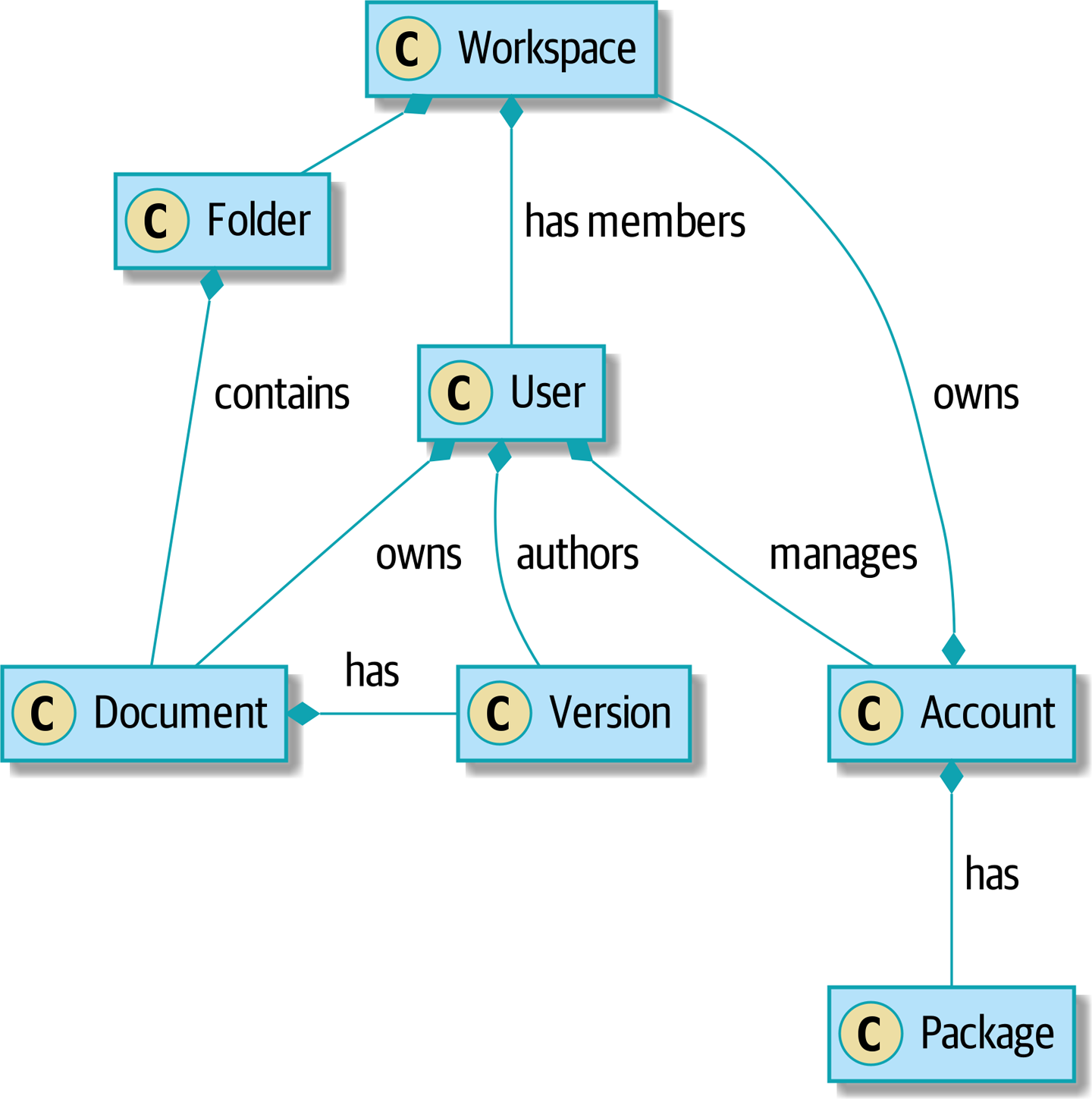
[plantuml, apwp_ep01, config=plantuml.cfg] @startuml scale 4 hide empty members Workspace *- Folder : contains Account *- Workspace : owns Account *-- Package : has User *-- Account : manages Workspace *-- User : has members User *-- Document : owns Folder *-- Document : contains Document *- Version: has User *-- Version: authors @enduml
这是 Bob 第一次学习如何分解泥潭的系统,而且它确实是一个难题。到处都是逻辑——在网页中、在管理器对象中、在助手程序中、在我们编写的用于抽象管理器和助手程序的胖服务类中,以及在我们编写的用于分解服务的复杂命令对象中。
如果您正在一个已经达到这种程度的系统中工作,情况可能会让人感到绝望,但开始清理杂草丛生的花园永远不会太晚。最终,我们聘请了一位懂得如何操作的架构师,他帮助我们重新控制了局面。
首先弄清楚您系统的用例。如果您有用户界面,它会执行哪些操作?如果您有后端处理组件,那么每个 cron 作业或 Celery 作业可能都是一个单独的用例。您的每个用例都需要有一个祈使式的名称:应用计费费用、清理废弃帐户或开具采购订单,例如。
在我们的例子中,我们的大多数用例都是管理器类的一部分,并且具有诸如创建工作区或删除文档版本之类的名称。每个用例都是从 Web 前端调用的。
我们的目标是为每个受支持的操作创建一个单独的函数或类,该函数或类负责协调要完成的工作。每个用例都应执行以下操作
-
如果需要,启动自己的数据库事务
-
获取任何所需数据
-
检查任何先决条件(请参阅 [appendix_validation] 中的 Ensure 模式)
-
更新领域模型
-
持久化任何更改
每个用例都应该作为一个原子单元成功或失败。您可能需要从另一个用例调用一个用例。这没关系;只需记下它,并尽量避免长时间运行的数据库事务。
|
注意
|
我们遇到的最大问题之一是管理器方法调用其他管理器方法,并且数据访问可能发生在模型对象本身。如果不进行遍布代码库的寻宝,就很难理解每个操作的作用。将所有逻辑拉到一个单独的方法中,并使用 UoW 来控制我们的事务,使系统更容易理解。 |
|
提示
|
如果用例函数中存在重复,那也没关系。我们不是要编写完美的代码;我们只是试图提取一些有意义的层。在几个地方复制一些代码比让用例函数在一个长链中相互调用要好。 |
这是一个将任何数据访问或协调代码从领域模型中拉出并放入用例的好机会。我们还应该尝试将 I/O 问题(例如,发送电子邮件、写入文件)从领域模型中拉出并放入用例函数中。我们应用了 [chapter_03_abstractions] 中关于抽象的技术,以使我们的处理程序即使在执行 I/O 时也保持单元可测试性。
这些用例函数主要关于日志记录、数据访问和错误处理。一旦您完成了这一步,您将掌握您的程序实际做什么,以及一种确保每个操作都有明确定义的开始和结束的方法。我们将朝着构建纯领域模型迈出一步。
阅读 Michael C. Feathers 的 Working Effectively with Legacy Code (Prentice Hall),以获得关于测试遗留代码和开始分离职责的指导。
识别聚合和有界上下文
我们的案例研究中代码库的问题之一是对象图高度连接。每个帐户都有许多工作区,每个工作区都有许多成员,所有成员都有自己的帐户。每个工作区包含许多文档,这些文档有许多版本。
您无法在类图中表达事物的完整恐怖程度。首先,实际上没有与用户相关的单个帐户。相反,有一个奇怪的规则,要求您枚举通过工作区与用户关联的所有帐户,并采用创建日期最早的帐户。
系统中的每个对象都是继承层次结构的一部分,该层次结构包括 SecureObject 和 Version。此继承层次结构直接反映在数据库架构中,因此每个查询都必须跨 10 个不同的表进行连接,并查看鉴别符列,才能知道您正在处理的对象类型。
代码库使您可以轻松地像这样“点”遍这些对象
user.account.workspaces[0].documents.versions[1].owner.account.settings[0];使用 Django ORM 或 SQLAlchemy 以这种方式构建系统很容易,但要避免。虽然它很方便,但它使性能推理变得非常困难,因为每个属性都可能触发对数据库的查找。
|
提示
|
聚合是一个一致性边界。一般来说,每个用例应该一次更新一个聚合。一个处理程序从仓库中获取一个聚合,修改其状态,并引发由此产生的任何事件。如果您需要来自系统另一部分的数据,使用读取模型完全没问题,但要避免在单个事务中更新多个聚合。当我们选择将代码分离到不同的聚合中时,我们明确选择使它们彼此之间最终一致。 |
许多操作需要我们以这种方式循环遍历对象——例如
# Lock a user's workspaces for nonpayment
def lock_account(user):
for workspace in user.account.workspaces:
workspace.archive()甚至递归遍历文件夹和文档的集合
def lock_documents_in_folder(folder):
for doc in folder.documents:
doc.archive()
for child in folder.children:
lock_documents_in_folder(child)这些操作扼杀了性能,但修复它们意味着放弃我们的单个对象图。相反,我们开始识别聚合并打破对象之间的直接链接。
|
注意
|
我们在 [chapter_12_cqrs] 中讨论了臭名昭著的 SELECT N+1 问题,以及当读取用于查询的数据与读取用于命令的数据时,我们可能选择使用不同的技术。 |
我们主要通过用标识符替换直接引用来做到这一点。
聚合前
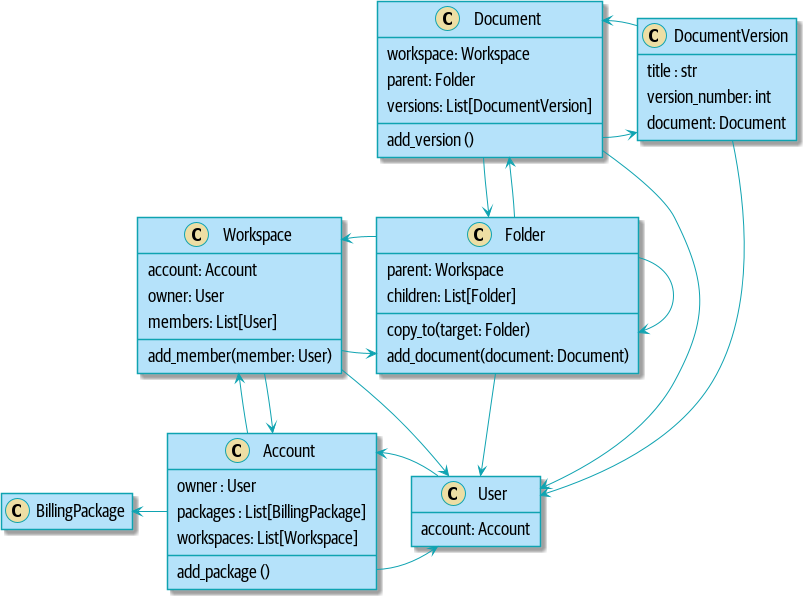
[plantuml, apwp_ep02, config=plantuml.cfg]
@startuml
scale 4
hide empty members
together {
class Document {
add_version()
workspace: Workspace
parent: Folder
versions: List[DocumentVersion]
}
class DocumentVersion {
title : str
version_number: int
document: Document
}
class Folder {
parent: Workspace
children: List[Folder]
copy_to(target: Folder)
add_document(document: Document)
}
}
together {
class User {
account: Account
}
class Account {
add_package()
owner : User
packages : List[BillingPackage]
workspaces: List[Workspace]
}
}
class BillingPackage {
}
class Workspace {
add_member(member: User)
account: Account
owner: User
members: List[User]
}
Account --> Workspace
Account -left-> BillingPackage
Account -right-> User
Workspace --> User
Workspace --> Folder
Workspace --> Account
Folder --> Folder
Folder --> Document
Folder --> Workspace
Folder --> User
Document -right-> DocumentVersion
Document --> Folder
Document --> User
DocumentVersion -right-> Document
DocumentVersion --> User
User -left-> Account
@enduml
使用聚合建模后
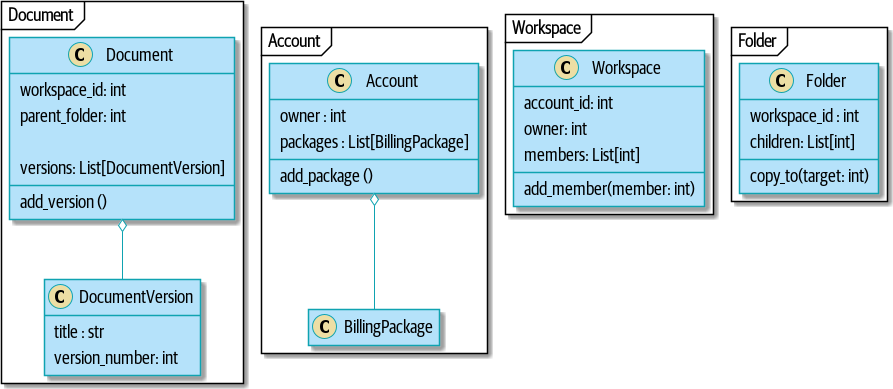
[plantuml, apwp_ep03, config=plantuml.cfg]
@startuml
scale 4
hide empty members
frame Document {
class Document {
add_version()
workspace_id: int
parent_folder: int
versions: List[DocumentVersion]
}
class DocumentVersion {
title : str
version_number: int
}
}
frame Account {
class Account {
add_package()
owner : int
packages : List[BillingPackage]
}
class BillingPackage {
}
}
frame Workspace {
class Workspace {
add_member(member: int)
account_id: int
owner: int
members: List[int]
}
}
frame Folder {
class Folder {
workspace_id : int
children: List[int]
copy_to(target: int)
}
}
Document o-- DocumentVersion
Account o-- BillingPackage
@enduml
|
提示
|
双向链接通常是您的聚合不正确的标志。在我们原始代码中,Document 知道其包含的 Folder,而 Folder 具有 Documents 的集合。这使得遍历对象图变得容易,但阻止我们正确思考我们所需的一致性边界。我们通过使用引用来分解聚合。在新模型中,Document 引用了其 parent_folder,但无法直接访问 Folder。 |
如果我们需要读取数据,我们避免编写复杂的循环和转换,并尝试用直接 SQL 替换它们。例如,我们的一个屏幕是文件夹和文档的树视图。
这个屏幕对数据库来说非常繁重,因为它依赖于嵌套的 for 循环,这些循环触发了延迟加载的 ORM。
|
提示
|
我们在 [chapter_12_cqrs] 中使用了相同的技术,我们在其中用简单的 SQL 查询替换了 ORM 对象上的嵌套循环。这是 CQRS 方法的第一步。 |
经过大量的绞尽脑汁,我们用一个又大又丑陋的存储过程替换了 ORM 代码。代码看起来很糟糕,但速度更快,并有助于打破 Folder 和 Document 之间的链接。
当我们需要写入数据时,我们一次更改一个聚合,并引入消息总线来处理事件。例如,在新模型中,当我们锁定一个帐户时,我们可以首先通过 SELECT id FROM workspace WHERE account_id = ? 查询所有受影响的工作区。
然后我们可以为每个工作区引发一个新命令
for workspace_id in workspaces:
bus.handle(LockWorkspace(workspace_id))通过绞杀者模式转向微服务的事件驱动方法
绞杀榕模式涉及在旧系统边缘周围创建一个新系统,同时保持旧系统运行。旧功能的一部分逐渐被拦截和替换,直到旧系统完全不做任何事情并且可以关闭。
在构建可用性服务时,我们使用了一种称为事件拦截的技术,将功能从一个地方移动到另一个地方。这是一个三步过程
-
引发事件以表示您要替换的系统中发生的更改。
-
构建第二个系统,该系统使用这些事件并使用它们来构建自己的领域模型。
-
用新的系统替换旧的系统。
我们使用事件拦截从 之前:基于 XML-RPC 的强双向耦合…

[plantuml, apwp_ep04, config=plantuml.cfg] @startuml Ecommerce Context !include images/C4_Context.puml LAYOUT_LEFT_RIGHT scale 2 Person_Ext(customer, "Customer", "Wants to buy furniture") System(fulfillment, "Fulfillment System", "Manages order fulfillment and logistics") System(ecom, "Ecommerce website", "Allows customers to buy furniture") Rel(customer, ecom, "Uses") Rel(fulfillment, ecom, "Updates stock and orders", "xml-rpc") Rel(ecom, fulfillment, "Sends orders", "xml-rpc") @enduml
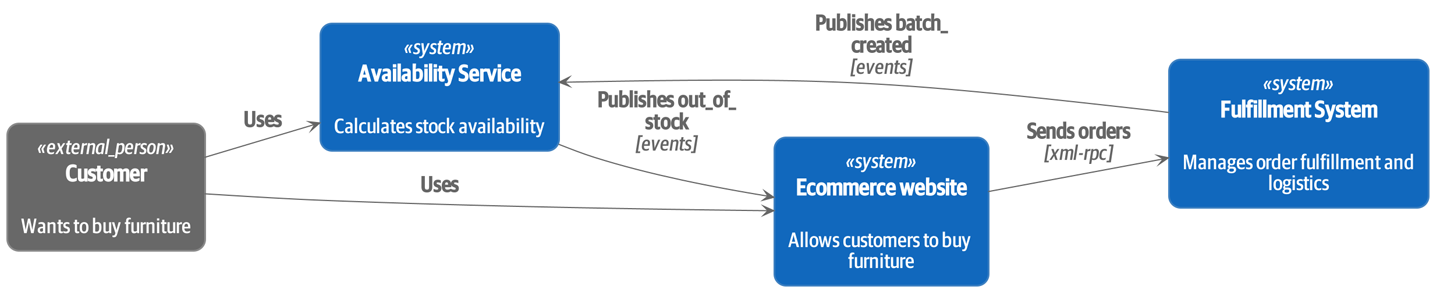
[plantuml, apwp_ep05, config=plantuml.cfg] @startuml Ecommerce Context !include images/C4_Context.puml LAYOUT_LEFT_RIGHT scale 2 Person_Ext(customer, "Customer", "Wants to buy furniture") System(av, "Availability Service", "Calculates stock availability") System(fulfillment, "Fulfillment System", "Manages order fulfillment and logistics") System(ecom, "Ecommerce website", "Allows customers to buy furniture") Rel(customer, ecom, "Uses") Rel(customer, av, "Uses") Rel(fulfillment, av, "Publishes batch_created", "events") Rel(av, ecom, "Publishes out_of_stock", "events") Rel(ecom, fulfillment, "Sends orders", "xml-rpc") @enduml
实际上,这是一个为期数月的项目。我们的第一步是编写一个可以表示批次、发货和产品的领域模型。我们使用 TDD 构建了一个玩具系统,该系统可以回答一个简单的问题:“如果我想要 N 个单位的 HAZARDOUS_RUG,它们需要多长时间才能交付?”
|
提示
|
在部署事件驱动系统时,从“可行骨架”开始。部署一个仅记录其输入的系统迫使我们解决所有基础设施问题,并开始在生产环境中工作。 |
一旦我们有了一个可用的领域模型,我们就转向构建一些基础设施组件。我们的第一个生产部署是一个微型系统,它可以接收 batch_created 事件并记录其 JSON 表示形式。这是事件驱动架构的“Hello World”。它迫使我们部署消息总线、连接生产者和消费者、构建部署管道并编写简单的消息处理程序。
有了部署管道、我们所需的基础设施和基本的领域模型,我们就开始了。几个月后,我们投入生产并为真实客户提供服务。
说服您的利益相关者尝试新事物
如果您正在考虑从一团巨大的泥潭中划分出一个新系统,您可能同时遇到可靠性、性能、可维护性或所有这三个方面的问题。根深蒂固、棘手的问题需要采取激烈的措施!
我们建议将领域建模作为第一步。在许多杂草丛生的系统中,工程师、产品负责人和客户不再使用相同的语言。业务利益相关者以抽象的、以流程为中心的术语谈论系统,而开发人员则被迫以系统在其狂野而混乱的状态下实际存在的形式谈论系统。
弄清楚如何建模您的领域是一项复杂的任务,这是许多优秀书籍的主题。我们喜欢使用交互式技术,如事件风暴和 CRC 建模,因为人类擅长通过游戏进行协作。事件建模是另一种将工程师和产品负责人聚集在一起,以命令、查询和事件的形式理解系统的技术。
|
提示
|
查看 www.eventmodeling.org 和 www.eventstorming.com,以获取一些关于使用事件对系统进行可视化建模的优秀指南。 |
目标是能够使用相同的通用语言来谈论系统,以便您可以就复杂性所在达成一致。
我们发现将领域问题视为 TDD kata 非常有价值。例如,我们为可用性服务编写的第一个代码是批次和订单行模型。您可以将其视为午餐时间研讨会,或作为项目开始时的快速原型。一旦您可以证明建模的价值,就更容易为构建项目以优化建模提出论据。
我们的技术审阅者提出的我们无法融入散文中的问题
以下是我们起草期间听到的一些问题,我们找不到一个好的地方在本书的其他地方解决这些问题
- 我需要一次完成所有这些吗?我可以一次只做一点吗?
-
不,您绝对可以逐步采用这些技术。如果您有一个现有系统,我们建议构建一个服务层,以尝试将协调放在一个地方。一旦您有了它,就更容易将逻辑推送到模型中,并将边缘问题(如验证或错误处理)推送到入口点。
即使您仍然有一个庞大而混乱的 Django ORM,也值得拥有一个服务层,因为这是一种开始理解操作边界的方法。
- 提取用例会破坏我的许多现有代码;它太混乱了
-
只需复制和粘贴。短期内造成更多重复是可以的。将此视为一个多步骤过程。您的代码现在处于糟糕的状态,因此请将其复制并粘贴到新位置,然后使新代码干净整洁。
完成此操作后,您可以将旧代码的使用替换为对新代码的调用,最后删除混乱的代码。修复大型代码库是一个混乱而痛苦的过程。不要期望事情会立即好转,也不要担心您的应用程序的某些部分仍然很混乱。
- 我需要做 CQRS 吗?这听起来很奇怪。我不能只使用仓库吗?
-
当然可以!我们在本书中介绍的技术旨在使您的生活更轻松。它们不是某种惩罚自己的苦行纪律。
在工作区/文档案例研究系统中,我们有很多 View Builder 对象,这些对象使用仓库来获取数据,然后执行一些转换以返回哑读取模型。这样做的好处是,当您遇到性能问题时,可以轻松地重写视图构建器以使用自定义查询或原始 SQL。
- 用例应该如何在更大的系统中交互?一个用例调用另一个用例有问题吗?
-
这可能是一个过渡步骤。同样,在文档案例研究中,我们有需要调用其他处理程序的处理程序。但这变得非常混乱,最好是使用消息总线来分离这些问题。
通常,您的系统将具有一个单一的消息总线实现和许多子域,这些子域以特定的聚合或一组聚合为中心。当您的用例完成时,它可以引发一个事件,并且其他地方的处理程序可以运行。
- 用例使用多个仓库/聚合是否是代码异味?如果是,为什么?
-
聚合是一个一致性边界,因此,如果您的用例需要原子地(在同一事务中)更新两个聚合,那么严格来说,您的一致性边界是错误的。理想情况下,您应该考虑移动到一个新的聚合,该聚合包装了您想要同时更改的所有内容。
如果您实际上只更新一个聚合,并将另一个聚合用于只读访问,那么这没问题,尽管您可以考虑构建一个读取/视图模型来获取该数据——如果每个用例只有一个聚合,则会使事情更简洁。
如果您确实需要修改两个聚合,但这两个操作不必在同一事务/UoW 中,请考虑将工作拆分为两个不同的处理程序,并使用领域事件在两者之间传递信息。您可以在 Vaughn Vernon 的 关于聚合设计的论文 中阅读更多内容。
- 如果我有一个只读但业务逻辑繁重的系统怎么办?
-
视图模型可以包含复杂的逻辑。在本书中,我们鼓励您分离读取和写入模型,因为它们具有不同的 一致性和吞吐量要求。大多数情况下,我们可以对读取使用更简单的逻辑,但这并非总是如此。特别是,权限和授权模型可能会为我们的读取端增加很多复杂性。
我们编写的系统中,视图模型需要广泛的单元测试。在这些系统中,我们从 视图获取器 中分离出一个 视图构建器,如 视图构建器和视图获取器(您可以在 cosmicpython.com 上找到此图的高分辨率版本) 中所示。
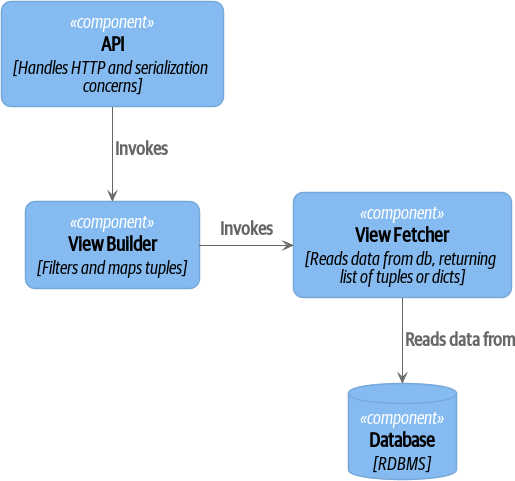
[plantuml, apwp_ep06, config=plantuml.cfg] @startuml View Fetcher Component Diagram !include images/C4_Component.puml ComponentDb(db, "Database", "RDBMS") Component(fetch, "View Fetcher", "Reads data from db, returning list of tuples or dicts") Component(build, "View Builder", "Filters and maps tuples") Component(api, "API", "Handles HTTP and serialization concerns") Rel(api, build, "Invokes") Rel_R(build, fetch, "Invokes") Rel_D(fetch, db, "Reads data from") @enduml
+ 这使得通过为其提供模拟数据(例如,字典列表)来轻松测试视图构建器。“花哨的 CQRS”与事件处理程序实际上是一种在每次写入时运行我们复杂的视图逻辑的方式,以便我们可以避免在读取时运行它。
- 我需要构建微服务来完成这些工作吗?
-
天哪,不需要!这些技术比微服务早了十年左右。聚合、领域事件和依赖倒置是控制大型系统复杂性的方法。只是当您为业务流程构建了一组用例和模型时,将其移动到自己的服务相对容易,但这并不是必需的。
- 我正在使用 Django。我还能做到这一点吗?
-
我们有一个专门为您准备的附录:[appendix_django]!
自毁装置
好的,所以我们给了您一大堆新玩具来玩。这是细则。Harry 和 Bob 不建议您将我们的代码复制并粘贴到生产系统中,并在 Redis pub/sub 上重建您的自动化交易平台。出于简洁和简单的原因,我们回避了很多棘手的主题。以下是我们认为您在真正尝试之前应该知道的一些事项列表。
- 可靠的消息传递很难
-
Redis pub/sub 不可靠,不应将其用作通用消息传递工具。我们选择它是因为它既熟悉又易于运行。在 MADE,我们运行 Event Store 作为我们的消息传递工具,但我们也有使用 RabbitMQ 和 Amazon EventBridge 的经验。
Tyler Treat 在他的网站 bravenewgeek.com 上发表了一些优秀的博客文章;您至少应该阅读 “您无法实现精确一次交付” 和 “您想要的是您不想要的:理解分布式消息传递中的权衡”。
- 我们明确选择可以独立失败的小型、集中的事务
-
在 [chapter_08_events_and_message_bus] 中,我们更新了我们的流程,以便取消分配订单行和重新分配订单行发生在两个独立的工作单元中。您将需要监控来了解这些事务何时失败,以及用于重放事件的工具。使用事务日志作为您的消息代理(例如,Kafka 或 EventStore)可以使其中一些操作更容易。您还可以查看 发件箱模式。
- 我们没有讨论幂等性
-
我们还没有真正考虑过当处理程序被重试时会发生什么。在实践中,你会希望使处理程序具有幂等性,这样用相同的消息重复调用它们不会对状态进行重复更改。这是构建可靠性的关键技术,因为它使我们能够在事件失败时安全地重试事件。
有很多关于幂等消息处理的优秀资料,可以尝试从 “如何在最终一致的 DDD/CQRS 应用程序中确保幂等性” 和 “(消息传递中的)不可靠性” 开始阅读。
- 你的事件模式会随着时间推移需要改变
-
你需要找到某种方法来记录你的事件,并与消费者分享模式。我们喜欢使用 JSON schema 和 markdown,因为它很简单,但也有其他的现有技术。Greg Young 写了一整本书关于随着时间推移管理事件驱动系统:《事件溯源系统中的版本控制》(Leanpub)。
更多必读资料
还有一些我们想推荐的书籍,以帮助你入门
-
Leonardo Giordani 撰写的《Python 整洁架构》(Leanpub) 于 2019 年出版,是为数不多的关于 Python 应用程序架构的早期书籍之一。
-
Gregor Hohpe 和 Bobby Woolf 合著的《企业集成模式》(Addison-Wesley Professional) 是学习消息传递模式的一个很好的起点。
-
Sam Newman 撰写的《从单体到微服务》(O’Reilly),以及 Newman 的第一本书《构建微服务》(O’Reilly)。书中提到了 Strangler Fig 模式(绞杀榕模式)等多种模式,并将其列为最受欢迎的模式之一。如果你正在考虑迁移到微服务,或者想了解集成模式以及基于异步消息传递的集成的注意事项,这些书都值得一看。